本文最后更新于 2025年5月15日 晚上
为了得到更好效果的 LoRA 模型,对着训练参数改了又改,再训练,测试,真的费时有费力啊,苦い。最近除了发现 Lokr 中 preset 对训练效果的影响外,还发现 debiased estimation loss 对训练效果的影响,就顺手记录一下吧。
使用工具
Kaggle,免费提供算力,每周可以使用 30h 的 Tesla T4 x 2,永远滴神。部署训练环境的脚本用了 SD Scripts Kaggle Jupyter NoteBook,自己写的工具用来部署训练环境挺方便的,训练工具就是 kohya-ss/sd-scripts 了。
训练参数
为了对比启用 debiased estimation loss 前后的训练效果,使用 konya_karasu 的图集作为训练集,用了 deepghs/waifuc 爬取图片并制作训练集,这个工具很方便的呢。
ill-xl-01-KonYa666_6
这是启用 debiased estimation loss 的训练参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| !python -m accelerate.commands.launch \
--num_cpu_threads_per_process=1 \
--multi_gpu \
--num_processes=2 \
"{SD_SCRIPTS_PATH}/sdxl_train_network.py" \
--pretrained_model_name_or_path="{SD_MODEL_PATH}/Illustrious-XL-v0.1.safetensors" \
--vae="{SD_MODEL_PATH}/sdxl_fp16_fix_vae.safetensors" \
--train_data_dir="{INPUT_DATASET_PATH}/konya_karasu" \
--output_name="ill-xl-01-KonYa666_6" \
--output_dir="{OUTPUT_PATH}/ill-xl-01-KonYa666_6" \
--log_tracker_name="Illustrious-XL-v0.1_LoRA" \
--prior_loss_weight=1 \
--resolution="1024,1024" \
--enable_bucket \
--min_bucket_reso=256 \
--max_bucket_reso=4096 \
--bucket_reso_steps=64 \
--save_model_as="safetensors" \
--save_precision="fp16" \
--save_every_n_epochs=2 \
--max_train_epochs=40 \
--train_batch_size=6 \
--gradient_checkpointing \
--network_train_unet_only \
--learning_rate=0.0001 \
--unet_lr=0.0001 \
--text_encoder_lr=0.00001 \
--lr_scheduler="constant_with_warmup" \
--lr_warmup_steps=100 \
--optimizer_type="Lion8bit" \
--network_module="lycoris.kohya" \
--network_dim=100000 \
--network_alpha=100000 \
--network_args \
conv_dim=100000 \
conv_alpha=100000 \
algo=lokr \
dropout=0 \
factor=8 \
train_norm=True \
preset="full" \
--optimizer_args \
weight_decay=0.05 \
betas="0.9,0.95" \
--log_with="{LOG_MODULE}" \
--logging_dir="{OUTPUT_PATH}/logs" \
--caption_extension=".txt" \
--shuffle_caption \
--keep_tokens=0 \
--max_token_length=225 \
--seed=1337 \
--mixed_precision="fp16" \
--xformers \
--cache_latents \
--cache_latents_to_disk \
--persistent_data_loader_workers \
--debiased_estimation_loss \
--full_fp16
|
ill-xl-01-KonYa666_7
在原来训练参数的基础上禁用了 debiased estimation loss。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| !python -m accelerate.commands.launch \
--num_cpu_threads_per_process=1 \
--multi_gpu \
--num_processes=2 \
"{SD_SCRIPTS_PATH}/sdxl_train_network.py" \
--pretrained_model_name_or_path="{SD_MODEL_PATH}/Illustrious-XL-v0.1.safetensors" \
--vae="{SD_MODEL_PATH}/sdxl_fp16_fix_vae.safetensors" \
--train_data_dir="{INPUT_DATASET_PATH}/konya_karasu" \
--output_name="ill-xl-01-KonYa666_7" \
--output_dir="{OUTPUT_PATH}/ill-xl-01-KonYa666_7" \
--log_tracker_name="Illustrious-XL-v0.1_LoRA" \
--prior_loss_weight=1 \
--resolution="1024,1024" \
--enable_bucket \
--min_bucket_reso=256 \
--max_bucket_reso=4096 \
--bucket_reso_steps=64 \
--save_model_as="safetensors" \
--save_precision="fp16" \
--save_every_n_epochs=2 \
--max_train_epochs=40 \
--train_batch_size=6 \
--gradient_checkpointing \
--network_train_unet_only \
--learning_rate=0.0001 \
--unet_lr=0.0001 \
--text_encoder_lr=0.00001 \
--lr_scheduler="constant_with_warmup" \
--lr_warmup_steps=100 \
--optimizer_type="Lion8bit" \
--network_module="lycoris.kohya" \
--network_dim=100000 \
--network_alpha=100000 \
--network_args \
conv_dim=100000 \
conv_alpha=100000 \
algo=lokr \
dropout=0 \
factor=8 \
train_norm=True \
preset="full" \
--optimizer_args \
weight_decay=0.05 \
betas="0.9,0.95" \
--log_with="{LOG_MODULE}" \
--logging_dir="{OUTPUT_PATH}/logs" \
--caption_extension=".txt" \
--shuffle_caption \
--keep_tokens=0 \
--max_token_length=225 \
--seed=1337 \
--mixed_precision="fp16" \
--xformers \
--cache_latents \
--cache_latents_to_disk \
--persistent_data_loader_workers \
--full_fp16
|
Loss
启用 debiased estimation loss 前后的 Loss 差别还很大欸,下面是 2 个 Loss 曲线的对比。
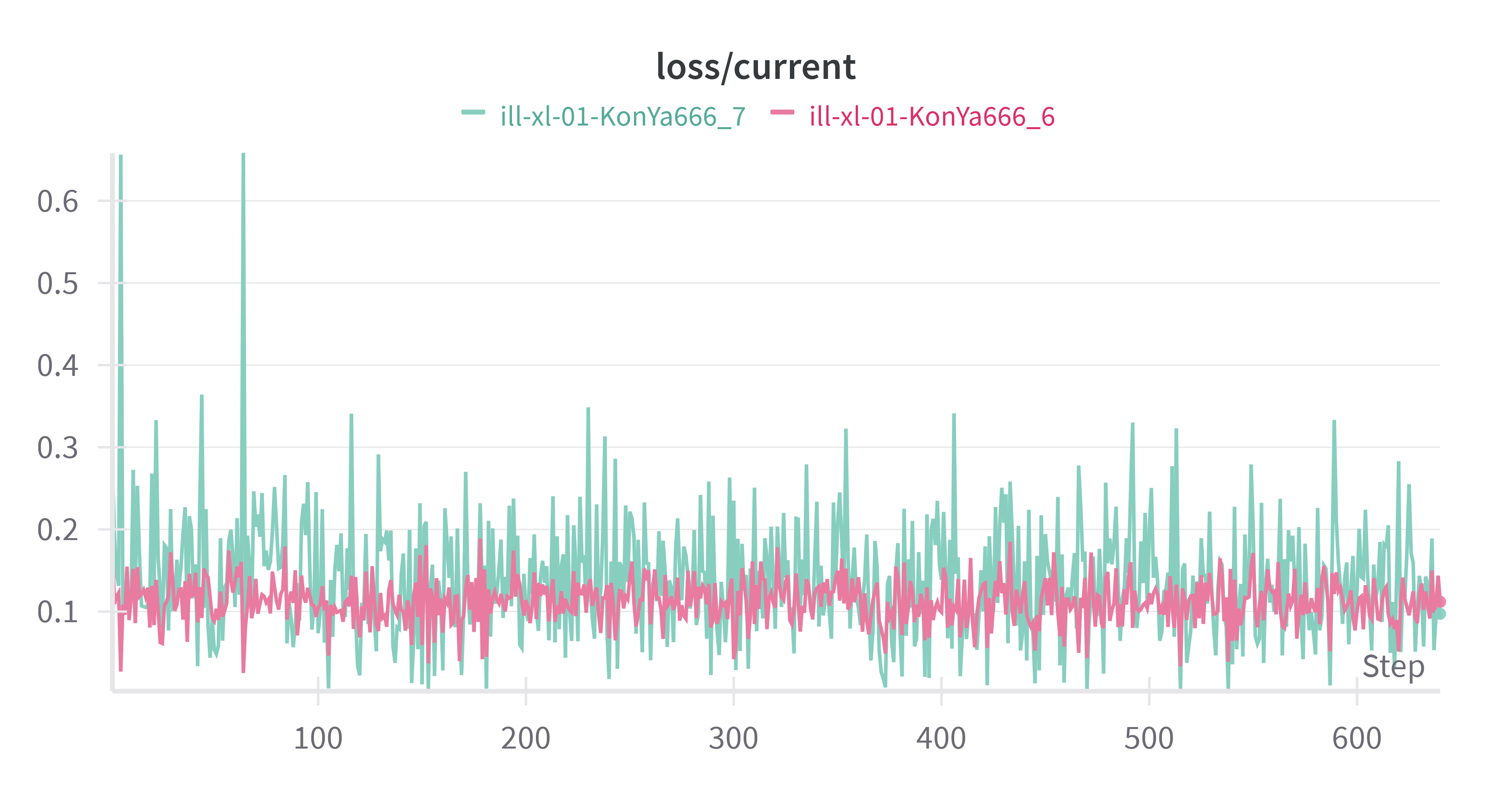
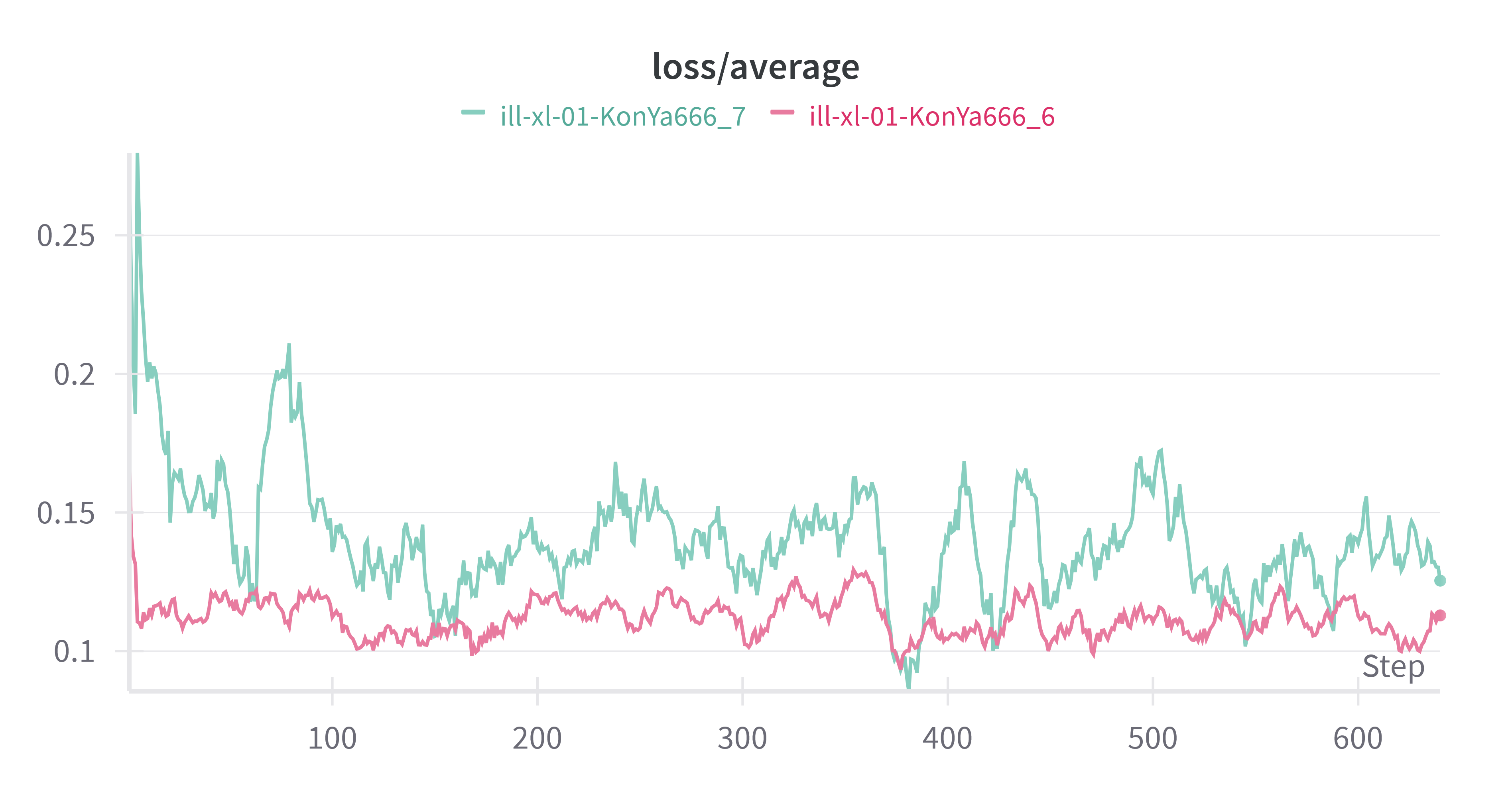
ill-xl-01-KonYa666_6 启用了 debiased estimation loss,相对于 ill-xl-01-KonYa666_7,Loss 曲线显得更加平稳,并且 Loss 值更低,收敛更快。
出图效果对比
用 XYZ 图对比了不同 Epoch 下 LoRA 的效果。

启用 debiased estimation loss 后学习速度很快,画风更加接近训练集,但似乎崩坏率有所提高,可能需要降低学习率吧。按照以前的经验来看,学习率偏高的时候肢体崩坏率会高一点。

没有启用 debiased estimation loss 时学习的速度相对慢了一些,但看起来肢体更好了一点。
在这 2 次训练中各挑出一个效果最好的进行测试吧。








虽然在前面的 XYZ 测试中测试了不同的 Epoch,并且发现启用了 debiased estimation loss 后肢体崩坏率有一点点高,但通过这部分的 XYZ 图对比,似乎启用 debiased estimation loss 前后的肢体表现都差不多。
画风表现方面,启用 debiased estimation loss 后画风学习得更好了,色彩看起来也更好。嗯…所以启用 debiased estimation loss 应该是更好的选择吧。
相关参考
对了,debiased estimation loss 这个东西有个相关的论文可以去看看,论文里面的内容就不在这讲了。
Arxiv:[2310.08442] Unmasking Bias in Diffusion Model Training。
一些优化
一次偶然,我和朋友练了同一个画风 LoRA,发现朋友训练的 LoRA 模型效果居然比我训练的 LoRA 效果好(太强了,膜拜),就用朋友的训练集再进行训练,在朋友训练参数的基础上加上了 debiased estimation loss。
ill-xl-10-zuu_2 使用了 debiased estimation loss 进行训练,zuustyle1 未使用 debiased estimation loss 进行训练,下面的图对比了一下效果。





之前认为肢体崩坏和学习率有关。嗯…想了想,一直使用高学习率可能会导致肢体崩坏率高一些吧,所以就把学习率优化器从 constant_with_warmup 换成了 cosine,修改后的训练参数如下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| !python -m accelerate.commands.launch \
--num_cpu_threads_per_process=1 \
--multi_gpu \
--num_processes=2 \
"{SD_SCRIPTS_PATH}/sdxl_train_network.py" \
--pretrained_model_name_or_path="{SD_MODEL_PATH}/Illustrious-XL-v0.1.safetensors" \
--vae="{SD_MODEL_PATH}/sdxl_fp16_fix_vae.safetensors" \
--train_data_dir="{INPUT_DATASET_PATH}/konya_karasu" \
--output_name="ill-xl-01-KonYa666_8" \
--output_dir="{OUTPUT_PATH}/ill-xl-01-KonYa666_8" \
--log_tracker_name="Illustrious-XL-v0.1_LoRA" \
--prior_loss_weight=1 \
--resolution="1024,1024" \
--enable_bucket \
--min_bucket_reso=256 \
--max_bucket_reso=4096 \
--bucket_reso_steps=64 \
--save_model_as="safetensors" \
--save_precision="fp16" \
--save_every_n_epochs=2 \
--max_train_epochs=40 \
--train_batch_size=6 \
--gradient_checkpointing \
--network_train_unet_only \
--learning_rate=0.0001 \
--unet_lr=0.0001 \
--text_encoder_lr=0.00001 \
--lr_scheduler="cosine" \
--lr_warmup_steps=0 \
--optimizer_type="Lion8bit" \
--network_module="lycoris.kohya" \
--network_dim=100000 \
--network_alpha=100000 \
--network_args \
conv_dim=100000 \
conv_alpha=100000 \
algo=lokr \
dropout=0 \
factor=8 \
train_norm=True \
preset="full" \
--optimizer_args \
weight_decay=0.05 \
betas="0.9,0.95" \
--log_with="{LOG_MODULE}" \
--logging_dir="{OUTPUT_PATH}/logs" \
--caption_extension=".txt" \
--shuffle_caption \
--keep_tokens=0 \
--max_token_length=225 \
--seed=1337 \
--mixed_precision="fp16" \
--xformers \
--cache_latents \
--cache_latents_to_disk \
--persistent_data_loader_workers \
--debiased_estimation_loss \
--full_fp16
|
下面是训练时 Loss 曲线的对比。
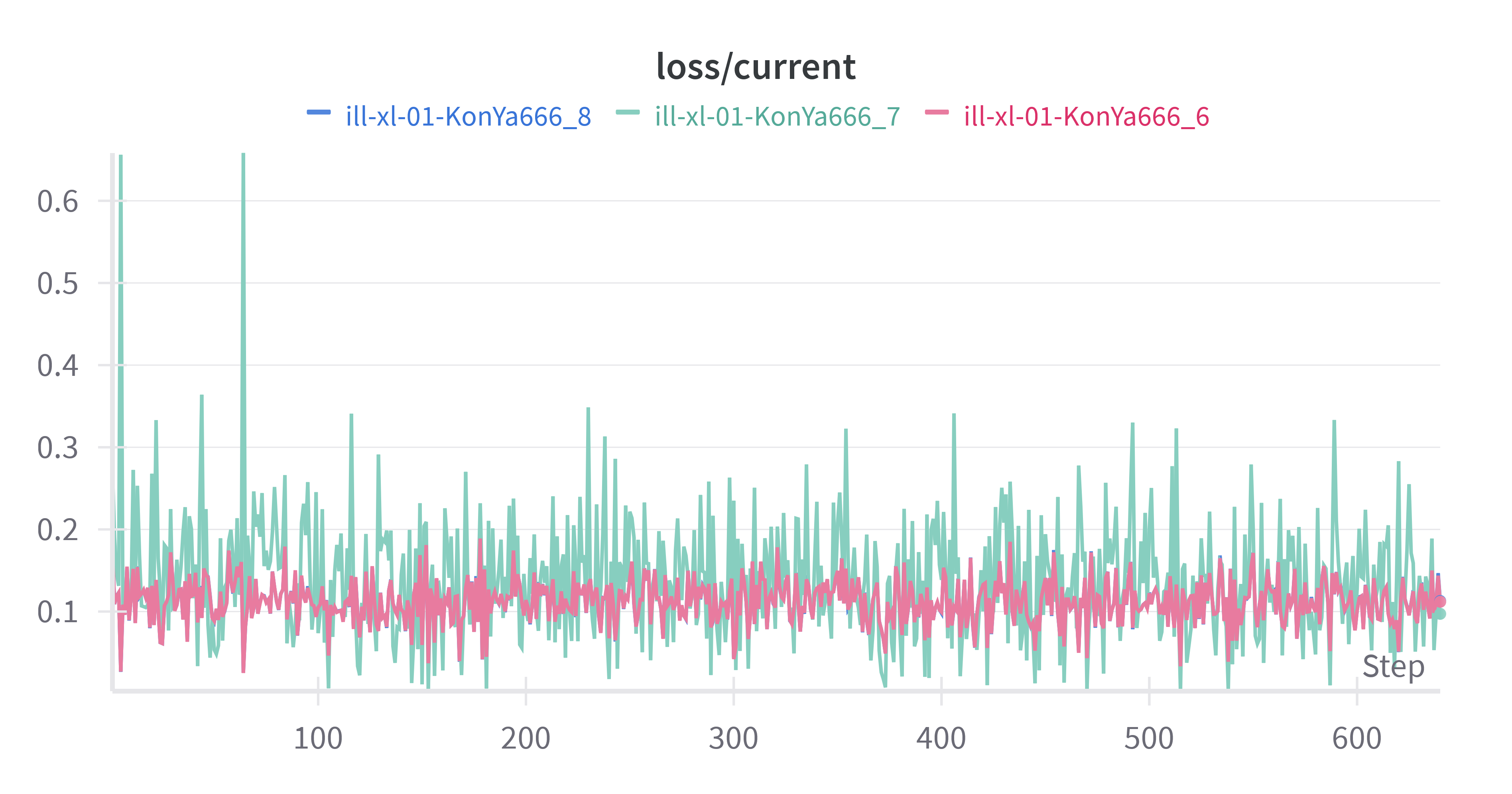
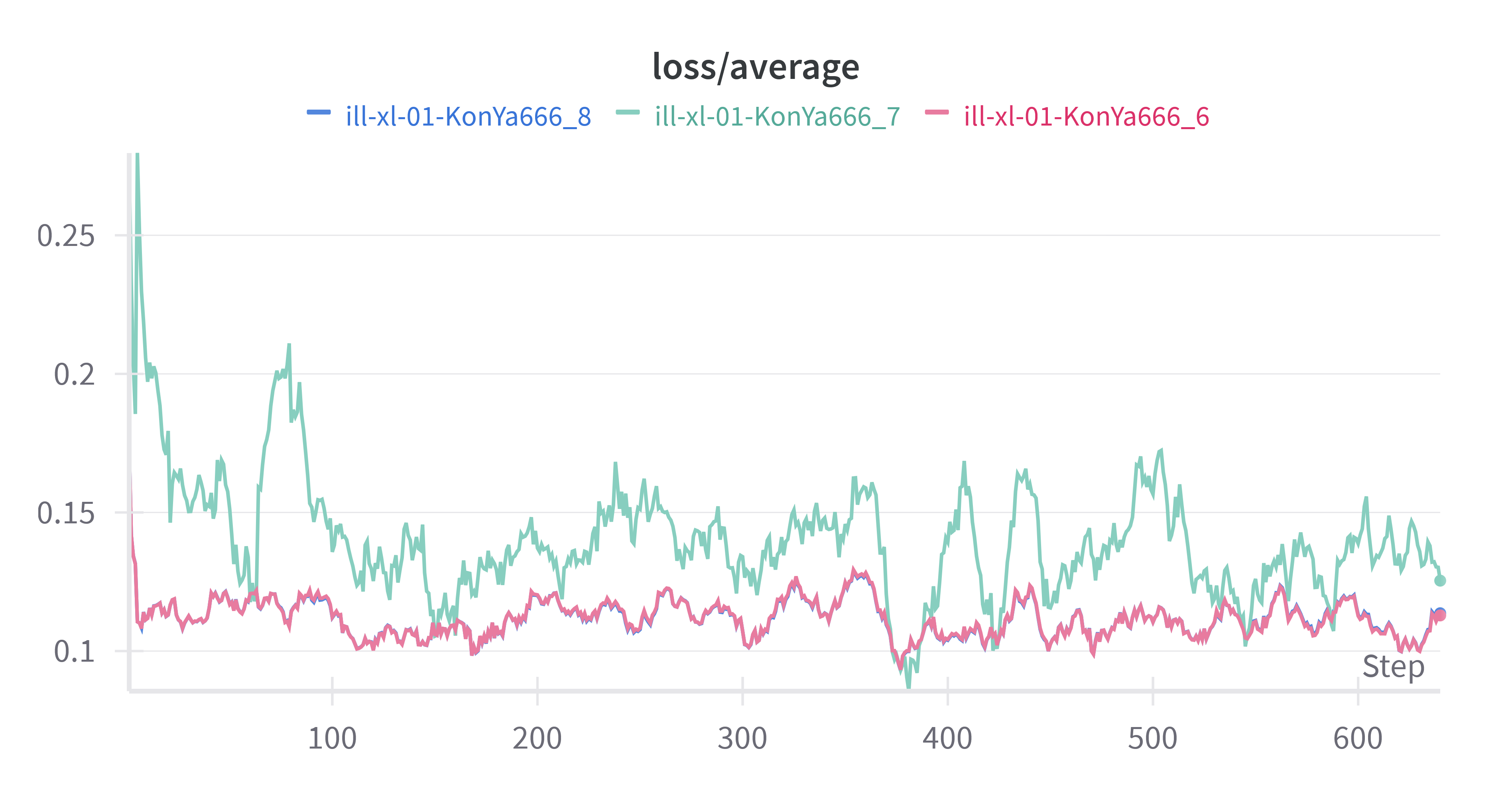
ill-xl-01-KonYa666_8 和 ill-xl-01-KonYa666_6 的 Loss 曲线几乎一致欸,再看看 XYZ 图下不同 Epoch 的对比。

相比于 ill-xl-01-KonYa666_6 和 ill-xl-01-KonYa666_7,ill-xl-01-KonYa666_8 有着比 ill-xl-01-KonYa666_6 更好的肢体,而且画风效果和 ill-xl-01-KonYa666_6 差不多,并且比 ill-xl-01-KonYa666_7 的画风更好。
从里面挑出一个效果比较好的 Epoch 和前面的进行对比。









效果就自己看看吧。