本文最后更新于 2026年3月25日 晚上
1. 前言
接触 AI 绘画后,想自己训练一个 LoRA 模型来实现自己想要的效果,但自己的显卡训练模型非常慢,或者显存太小无法训练,此时就可以通过云端进行模型训练。
2. 使用工具
这里我使用 SD-Trainer 提供的打标器对图片进行打标,使用 SD-Trainer Installer 进行安装。
云端训练使用的是 Kaggle 平台,使用邮箱注册并且绑定手机号。
云端训练脚本使用的是 SD Scripts Kaggle Jupyter NoteBook,该脚本将会部署 sd-scripts 进行 Stable Diffusion 模型训练。
为了方便存储模型和训练集,使用 HuggingFace 和 ModelScope 平台,这 2 个平台的使用教程可以阅读《使用 HuggingFace / ModelScope 保存和下载文件》这篇文章。
3. 准备训练集
一般想训练出比较好效果的 LoRA,训练集最好准备 50 张以上的图片。
Kaggle 不允许上传或者生成 NSFW 内容,所以训练集不能包含 NSFW 的内容,否则将导致 Kaggle 账号被封禁!
千万千万千万不要尝试上传 NSFW 内容到 Kaggle 中,真的会导致 Kaggle 账号被封禁!!!
为了方便演示,所以只准备了 3 张图片,下面是训练集的结构。
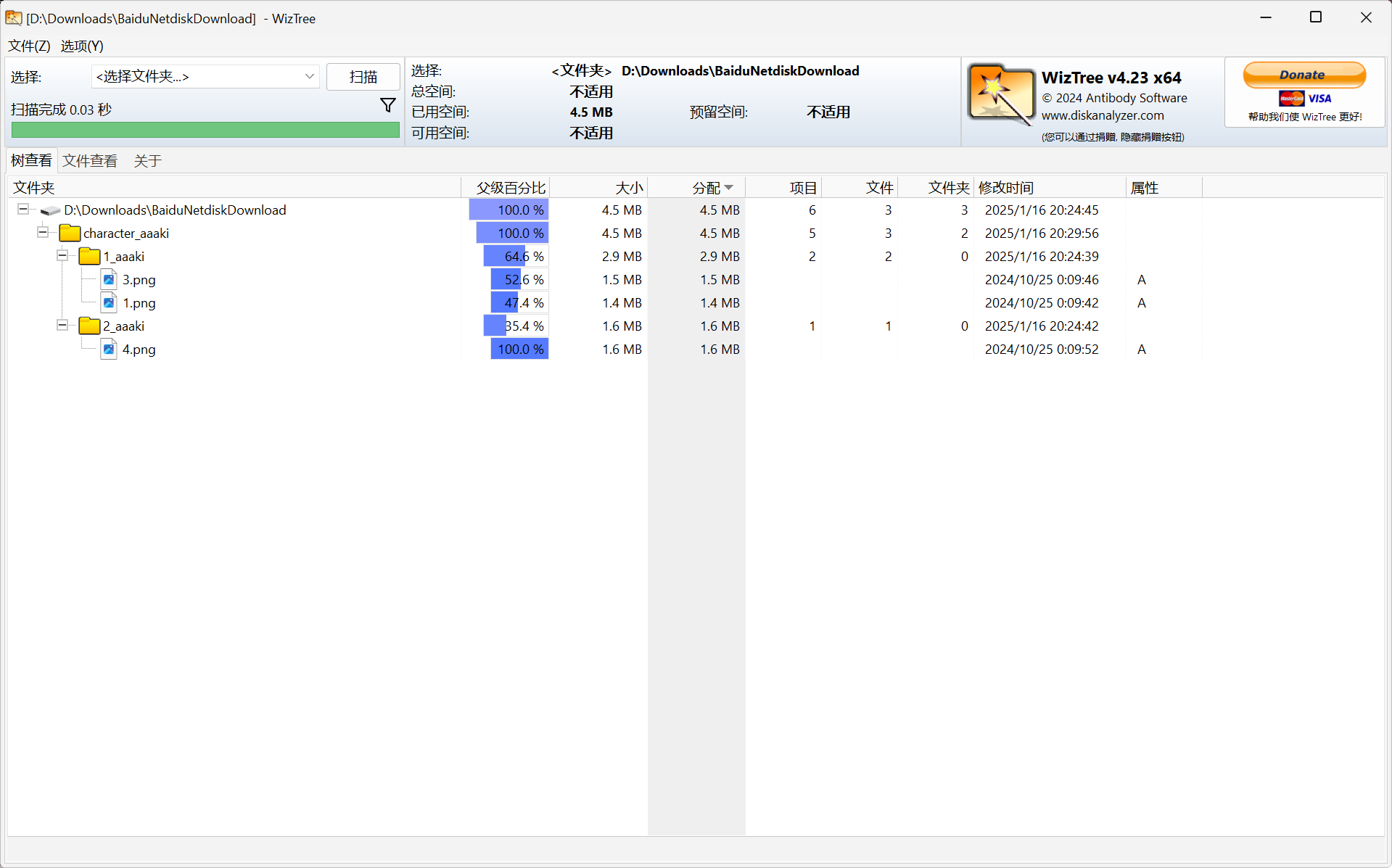
character_aaaki 为训练集的名称,填写训练集路径时,只能填到 character_aaaki 这一层路径,不能继续将路径深入。
在 character_aaaki 这个文件夹下是不同子文件夹,并且按照{重复次数}_{子训练集名称}这个格式进行命名,则 1_aaaki 这个子训练集在每轮训练时,里面的图片只会被训练 1 次,而 2_aaaki 这个子训练集中的图片会被训练 2 次。
子训练集的数量和子训练集设置的重复次数根据自己的训练素材来设置。
在子训练集中存放的则是图片,模型在训练时将会学习图片中的特征,但这些图片缺少标注,所以使用打标器对图片进行内容标注。
4. 图片标注
这里需要对 1_aaaki 和 2_aaaki 这 2 个子训练集进行打标,使用 SD-Trainer 中的打标工具。
打开 SD-Trainer 后,进入 WD 标签器,在图片文件夹路径填写子训练集的路径,Tagger 模型选择 wd-eva02-large-tagger-v3(这个打标模型的标注比较详细,不过选择其他 Tagger 模型也可以)。
因为我训练的是人物 LoRA,需要为人物 LoRA 设置触发词,所以在附加提示词 (逗号分隔)中填写了触发词,如果训练的是画风 LoRA,则一般不需要设置触发词。
这里将将结果中的括号进行转义处理取消勾选,因为训练脚本所使用的 sd-scripts 不需要对标注文本中的括号进行转义处理。
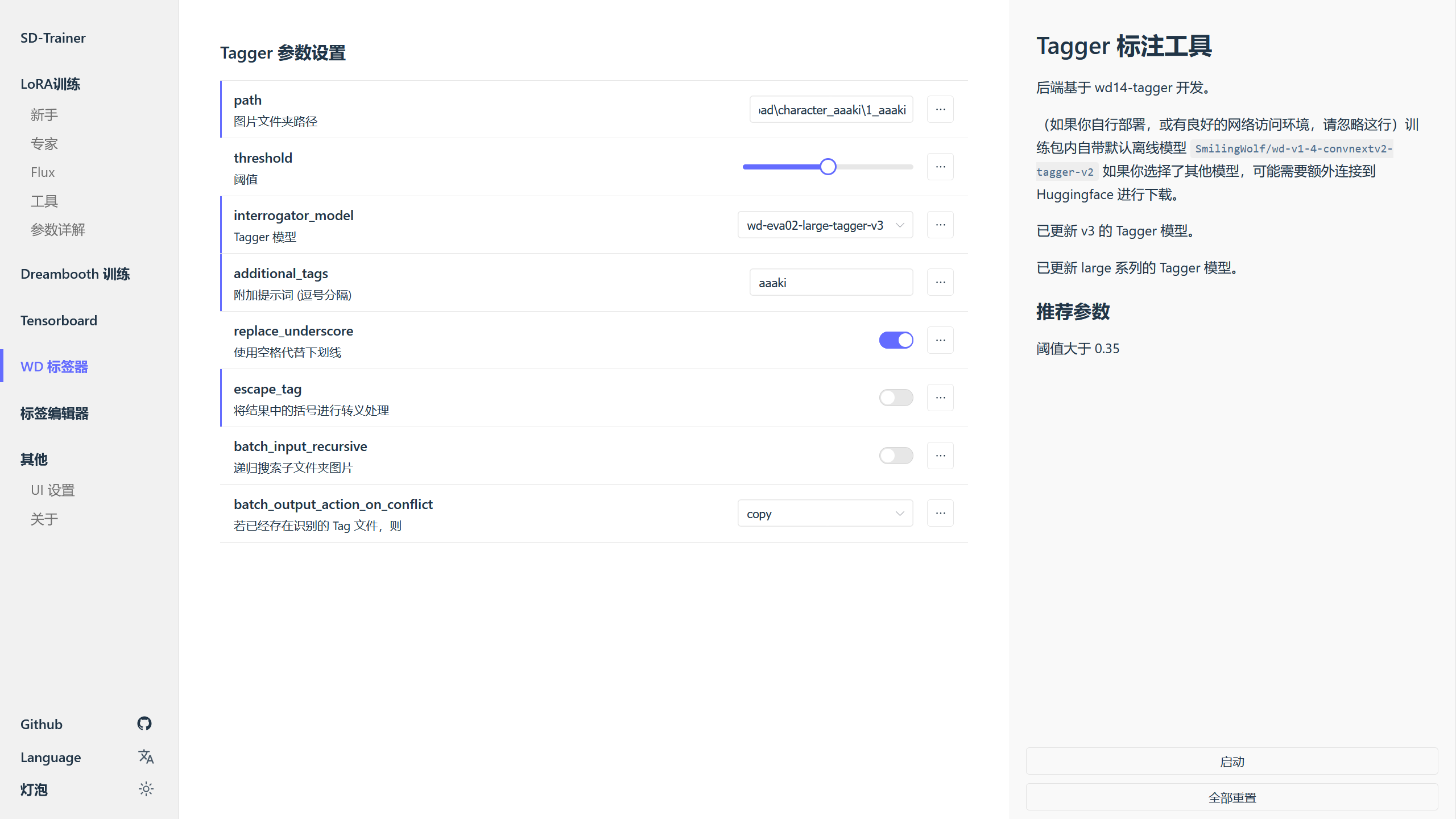
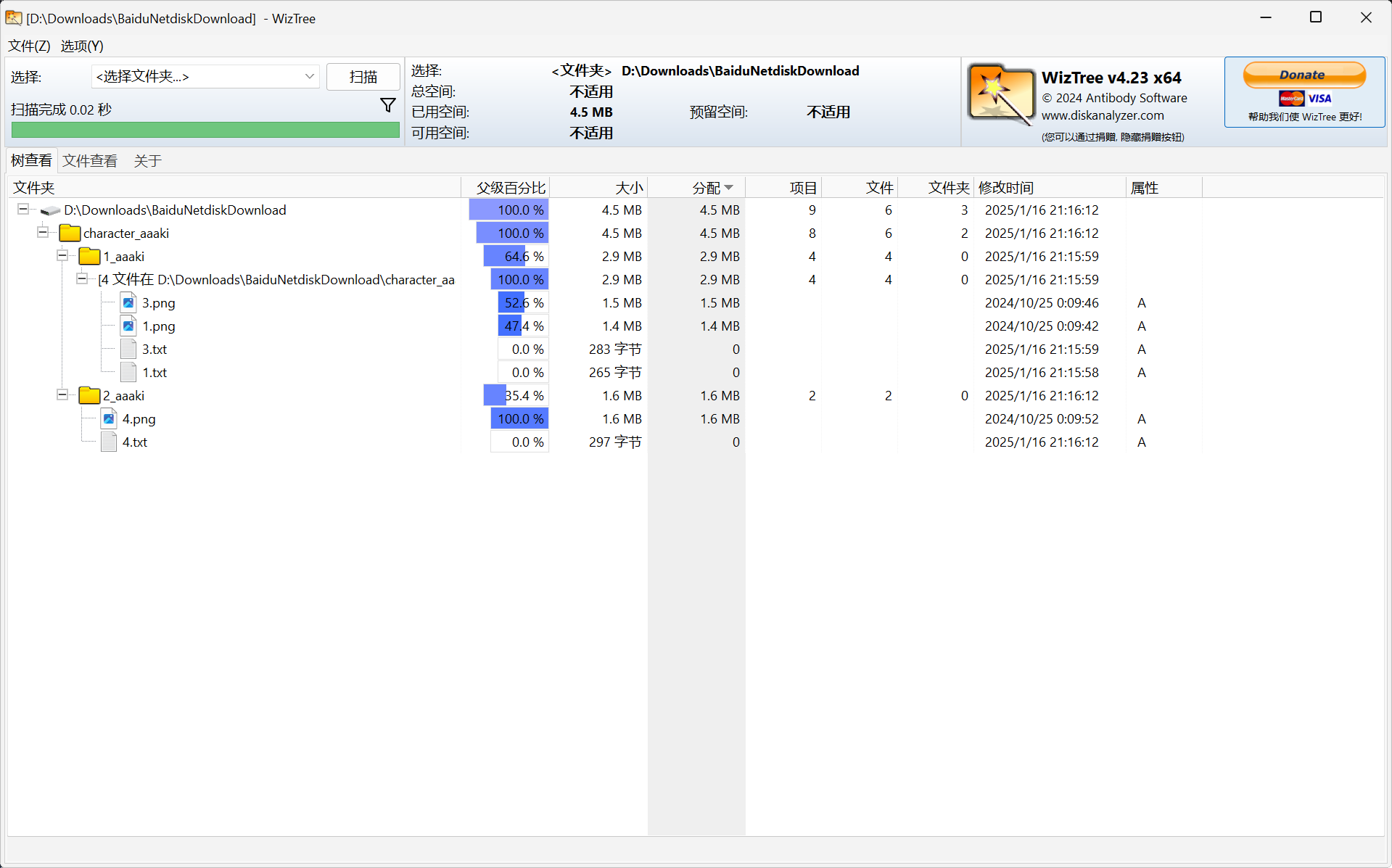
配置完成后点击右边的启动按钮对子训练集中的图片进行标注,将子训练集分别进行打标处理后,训练集结构如下。
5. 配置 Kaggle 训练脚本
处理完训练集后,现在对云端的训练脚本进行配置,进入 sd-webui-all-in-one 项目地址,找到 SD Scripts Kaggle Jupyter NoteBook 后,点击 sd_scripts_kaggle.ipynb 下载该训练脚本。
进入 Kaggle 官网,点击左侧的 Code(代码),在 Code(代码)界面点击 Your Work(个人工作),在该界面可以看到自己创建的 Notebooks(基于 Jupyter 的笔记本)。点击上方的 Create(创建)-> New Notebook(新建笔记本),此时将新建一个新的笔记本并打开编辑界面。
在编辑界面的顶部点击 File(文件)-> Import Notebook(导入笔记本),在右侧的导入界面选择刚刚下载下来的 sd_scripts_kaggle.ipynb,再点击下方的 Import(导入)将训练脚本导入 Kaggle。
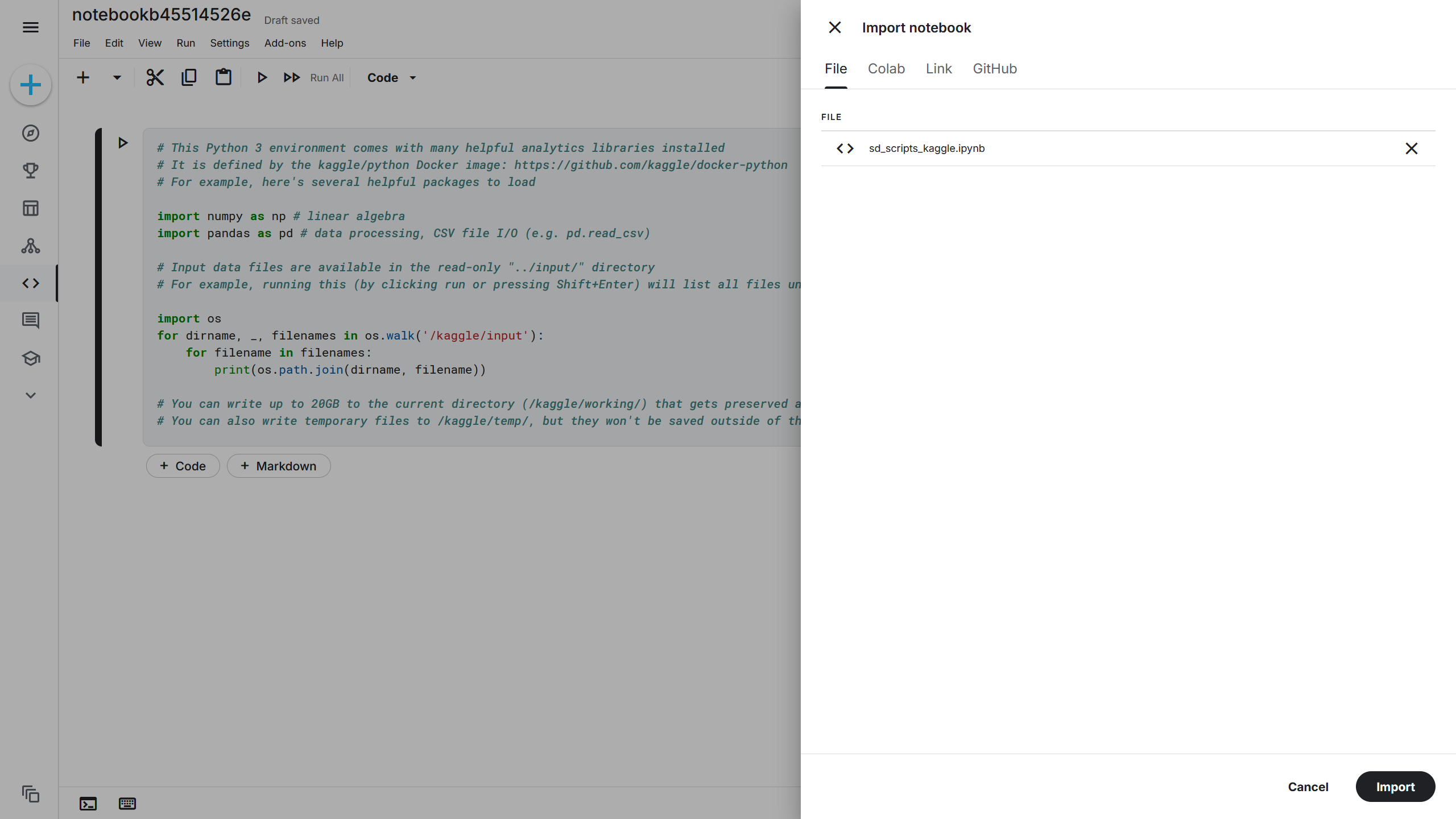
将 sd_scripts_kaggle.ipynb 导入后,如果右侧没有看到 Kaggle Notebook 的配置界面,可以点击右下角的小三角箭头打开,然后在右侧 Notebook(笔记本)-> Session options(会话选项)-> ACCELERATOR(加速器)选项选择 GPU T4 x 2,此时训练脚本基本配置完成。
6. 配置训练脚本参数
该训练脚本主要分为 6 大部分,第 1 部分是训练脚本的简单说明,第 2 部分则是该训练脚本的功能初始化单元,该部分包含大量处理训练环境的函数,如果对训练脚本功能的具体代码实现感兴趣,可以阅读该部分的代码,否则直接忽略该部分。
在每个大标题的下方包含下一个单元和上一个单元按钮,点击按钮可以快速跳转笔记本不同的单元。
下一个单元是参数配置单元,这里设置了在 Kaggle 部署训练环境的不同参数。
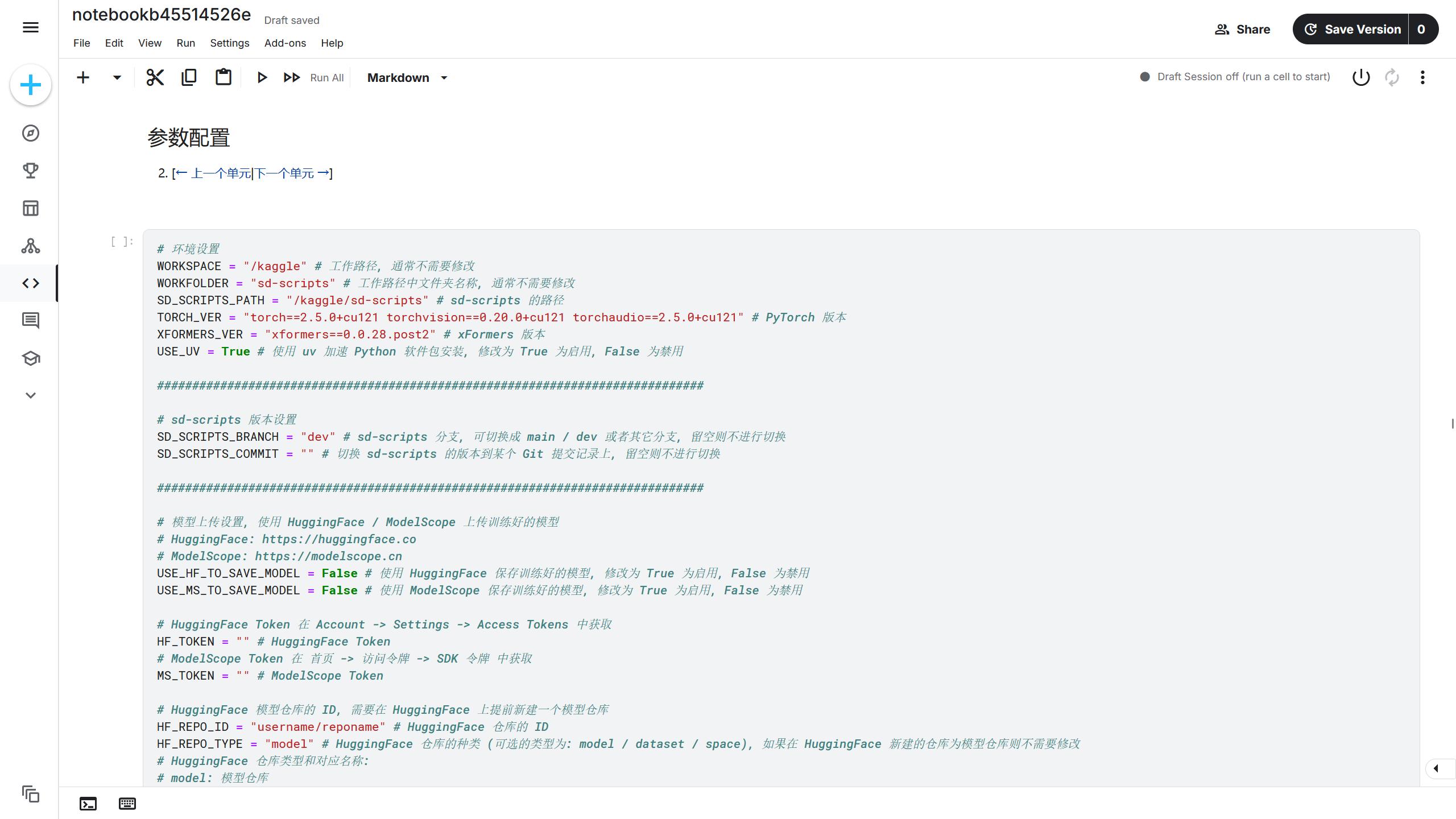
环境设置中的内容通常不需要修改,保持默认即可。
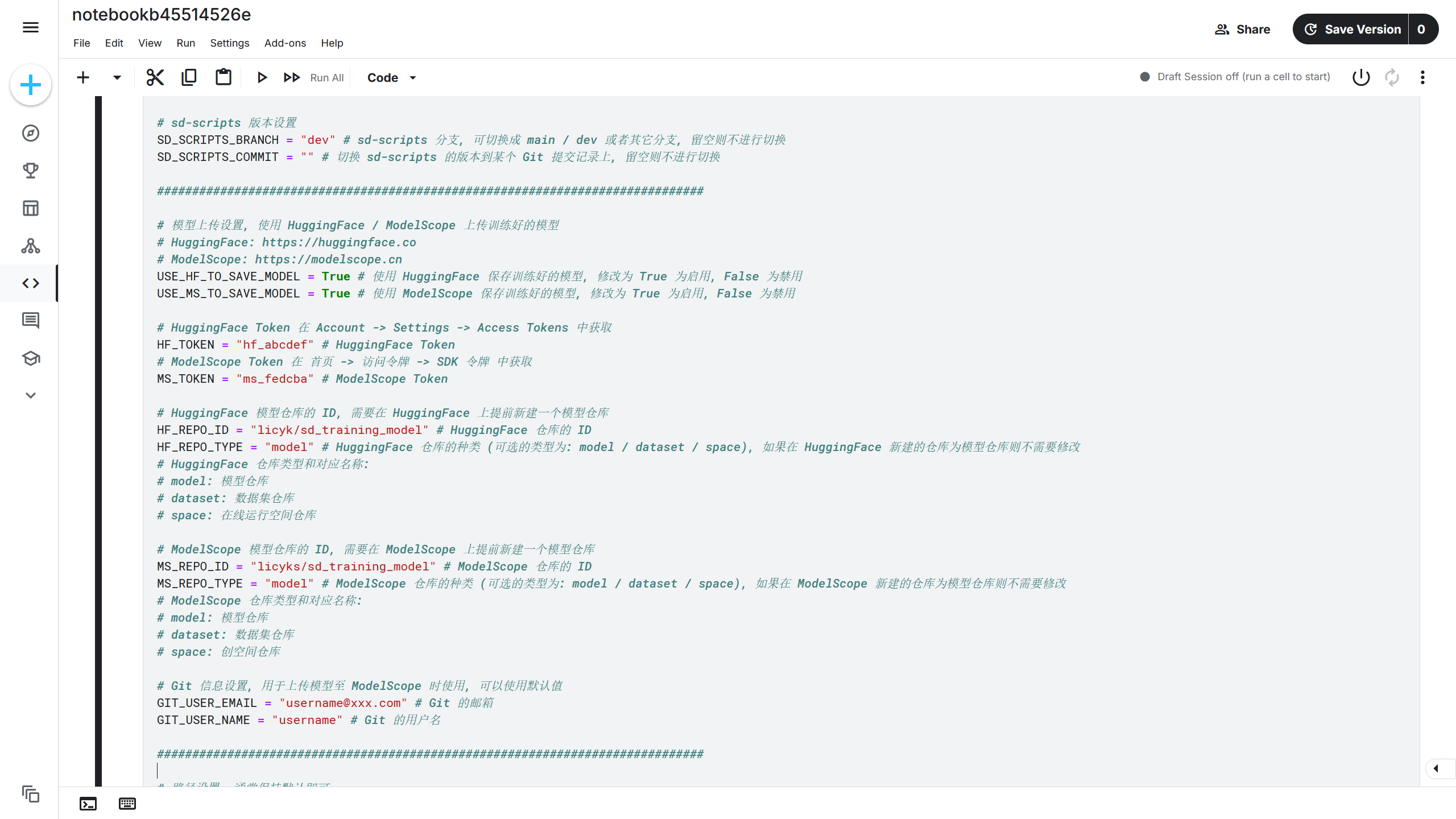
sd-scripts 版本设置设置了使用 sd-scripts 的分支和版本,这里可以看 sd-scripts 在 Github 的项目。
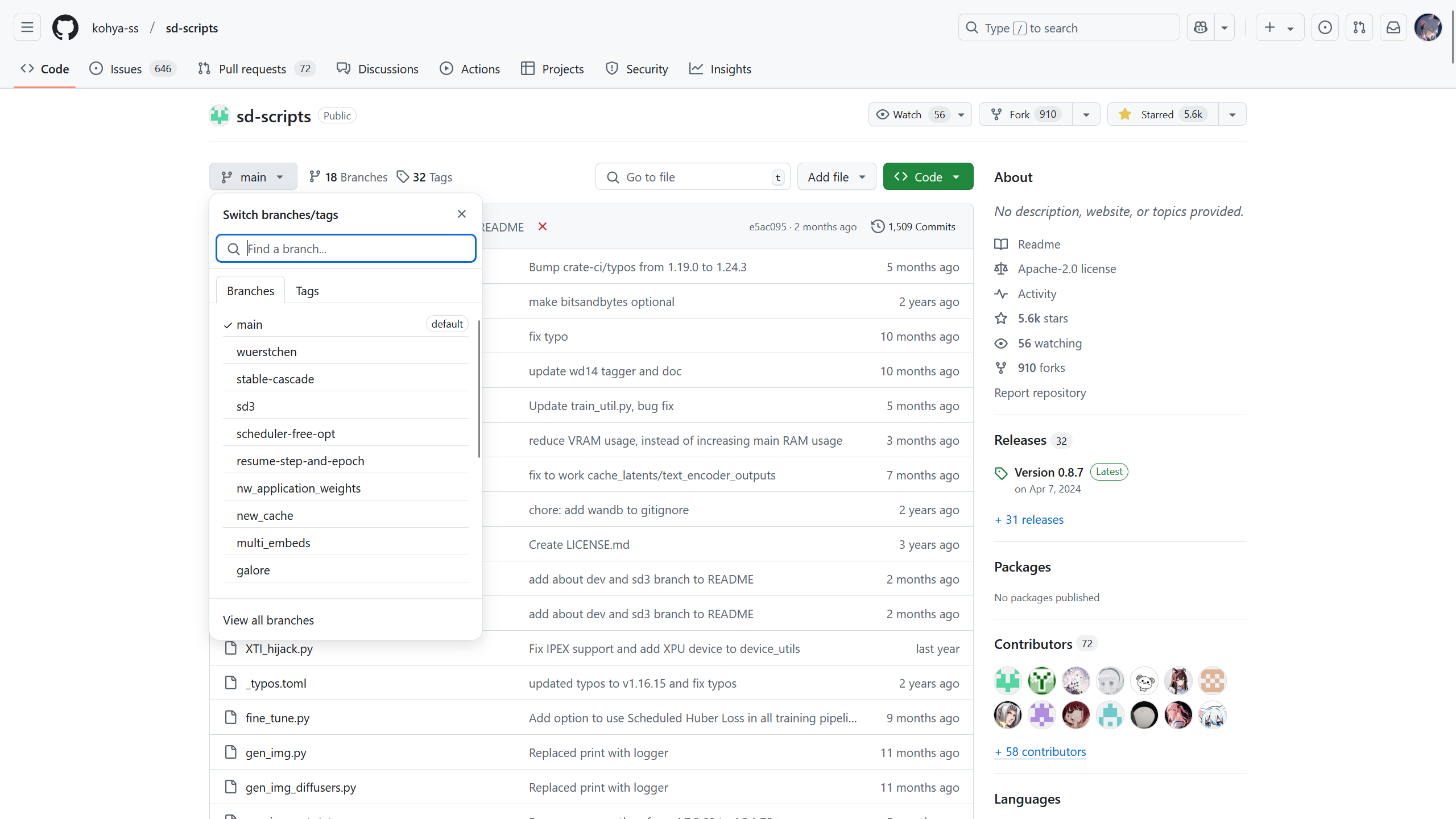
在该项目的左上角为项目的分支,不同的分支功能会有些差异,稳定性不同,通常使用 dev 分支即可,右上角为 Commits(提交记录),该项目每更新一次时将生成一个新的 Commit(提交记录)对应的哈希值,可以通过该哈希值切换版本。
sd-scripts 版本设置通常不需要修改。
模型上传设置设置训练结束后将模型上传到 HuggingFace / ModelScope。如果没有设置该选项,在训练结束后,只能从 Kaggle Output 中下载训练好的模型。这里推荐启用该选项,则将USE_HF_TO_SAVE_MODEL和USE_MS_TO_SAVE_MODEL的值从False设置为True。
设置后,需要分别获取 HuggingFace Token 和 ModelScope Token。
进入 HuggingFace 官网后,点击右上角头像打开菜单,选择 Access Tokens -> Create new token,在 Token name(密钥名字)随便填写一个名字,然后在 Repositories(仓库)选项将下方的 3 个选项勾选,再点击下方的 Create token(创建密钥),此时将获得 HuggingFace Token,复制下来并保管好,比如获取到的 HuggingFace Token 为hf_abcdef。
进入 ModelScope 官网后,点击首页 -> 访问令牌 -> SDK 令牌 -> 新建 SDK 令牌,输入名称后点击新建令牌,再将 SDK 令牌复制下来并保管好,比如刚刚获取到的 ModelScope SDK 令牌(ModelScope Token)为ms_fedcba。
获取到 HuggingFace Token 和 ModelScope SDK 令牌后,将训练脚本的HF_TOKEN值修改为hf_abcdef,即HF_TOKEN = "hf_abcdef"。将MS_TOKEN的值修改为ms_fedcba,即MS_TOKEN = "ms_fedcba"。
HuggingFace Token 和 ModelScope Token 除了用于上传模型,也可用于下载模型。
部分 HuggingFace / ModelScope 仓库需要访问权限,比如 black-forest-labs/FLUX.1-dev,该仓库需要申请访问权限后才能访问,如果使用 Api 进行访问时(该训练脚本中使用的一些工具就基于 Api 进行访问),就需要 Token 来获取访问权限和下载权限。
如果是访问自己的私有仓库中的模型或者其他文件,也需要使用 Token 来获取权限。
接下来在 HuggingFace 和 ModelScope 分别创建一个模型仓库。
此时在 HuggingFace 上创建的模型仓库 ID 为licyk/sd_training_model,在 ModelScope 上创建的模型仓库 ID 为licyks/sd_training_model。
得到 HuggingFace 仓库 ID 后,将HF_REPO_ID的值设置为 HuggingFace 上创建的模型仓库 ID,即licyk/sd_training_model,将HF_REPO_TYPE的值修改为model。
得到 ModelScope 仓库 ID 后,将MS_REPO_ID的值设置为 ModelScope 上创建的模型仓库 ID,即licyks/sd_training_model,将MS_REPO_TYPE的值修改为model。
如果手动不创建仓库也是可以的,填写好仓库 ID 后,当上传模型到仓库时,会自动检查仓库是否存在,如果不存在则自动创建一个新的仓库用于模型上传。
不过后续的某些步骤还是需要手动创建一个仓库,比如将自己的模型上传到 HuggingFace 中,再下载到 Kaggle 中。所以还是手动创建一个仓库吧。
Git 信息设置通常使用默认值即可,无需配置。
路径设置配置了一些预设路径,通常不需要修改。
训练模型设置提供了一部分常用的大模型和 VAE 模型,可以根据自己训练的要求进行选择。
在模型列表中,前面部分的为模型下载链接,后面为数字,当数字设置为 1 时,模型将会被下载。设置为其他数字时,模型将不会被下载。
例如["https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/v1-5-pruned-emaonly.safetensors", 0],和["https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/animefull-final-pruned.safetensors", 1],,当在进行环境安装时,前面的模型不会被下载,后面的模型将被下载,并且模型的名称为animefull-final-pruned.safetensors。
模型将会下载到{SD_MODEL_PATH},即/kaggle/sd-models。
下面是配置好的训练脚本参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
|
WORKSPACE = "/kaggle"
WORKFOLDER = "sd-scripts"
SD_SCRIPTS_REPO = "https://github.com/kohya-ss/sd-scripts"
SD_SCRIPTS_REQUIREMENT = "requirements.txt"
TORCH_VER = "torch==2.5.1+cu124 torchvision==0.20.1+cu124 torchaudio==2.5.1+cu124"
XFORMERS_VER = "xformers==0.0.28.post3"
USE_UV = True
PIP_INDEX_MIRROR = "https://pypi.python.org/simple"
PIP_EXTRA_INDEX_MIRROR = "https://download.pytorch.org/whl/cu124"
PYTORCH_MIRROR = "https://download.pytorch.org/whl/cu124"
PIP_FIND_LINKS_MIRROR = "https://download.pytorch.org/whl/cu121/torch_stable.html"
HUGGINGFACE_MIRROR = "https://hf-mirror.com"
GITHUB_MIRROR = [
"https://ghfast.top/https://github.com",
"https://mirror.ghproxy.com/https://github.com",
"https://ghproxy.net/https://github.com",
"https://gh.api.99988866.xyz/https://github.com",
"https://gh-proxy.com/https://github.com",
"https://ghps.cc/https://github.com",
"https://gh.idayer.com/https://github.com",
"https://ghproxy.1888866.xyz/github.com",
"https://slink.ltd/https://github.com",
"https://github.boki.moe/github.com",
"https://github.moeyy.xyz/https://github.com",
"https://gh-proxy.net/https://github.com",
"https://gh-proxy.ygxz.in/https://github.com",
"https://wget.la/https://github.com",
"https://kkgithub.com",
"https://gitclone.com/github.com",
]
CHECK_AVALIABLE_GPU = False
RETRY = 3
DOWNLOAD_THREAD = 16
ENABLE_TCMALLOC = True
ENABLE_CUDA_MALLOC = True
UPDATE_CORE = True
SD_SCRIPTS_BRANCH = "sd3"
SD_SCRIPTS_COMMIT = ""
USE_HF_TO_SAVE_MODEL = True
USE_MS_TO_SAVE_MODEL = True
HF_TOKEN = "hf_abcdef"
MS_TOKEN = "ms_fedcba"
HF_REPO_ID = "licyk/sd_training_model"
HF_REPO_TYPE = "model"
MS_REPO_ID = "licyks/sd_training_model"
MS_REPO_TYPE = "model"
HF_REPO_VISIBILITY = False
MS_REPO_VISIBILITY = False
GIT_USER_EMAIL = "username@example.com"
GIT_USER_NAME = "username"
LOG_MODULE = "tensorboard"
WANDB_TOKEN = ""
INPUT_DATASET_PATH = "/kaggle/dataset"
OUTPUT_PATH = "/kaggle/working/model"
SD_MODEL_PATH = "/kaggle/sd-models"
KAGGLE_INPUT_PATH = "/kaggle/input"
SD_MODEL = [
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/v1-5-pruned-emaonly.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/animefull-final-pruned.safetensors", 1),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/Counterfeit-V3.0_fp16.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/cetusMix_Whalefall2.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/cuteyukimixAdorable_neochapter3.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/ekmix-pastel-fp16-no-ema.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/ex2K_sse2.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/kohakuV5_rev2.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/meinamix_meinaV11.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/oukaStar_10.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/pastelMixStylizedAnime_pastelMixPrunedFP16.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/rabbit_v6.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/sweetSugarSyndrome_rev15.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/AnythingV5Ink_ink.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/bartstyledbBlueArchiveArtStyleFineTunedModel_v10.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/meinapastel_v6Pastel.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/qteamixQ_omegaFp16.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/tmndMix_tmndMixSPRAINBOW.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/sd_xl_base_1.0_0.9vae.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/animagine-xl-3.0.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/AnythingXL_xl.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/abyssorangeXLElse_v10.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/animaPencilXL_v200.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/animagine-xl-3.1.safetensors", 1),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/heartOfAppleXL_v20.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/baxlBartstylexlBlueArchiveFlatCelluloid_xlv1.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/kohaku-xl-delta-rev1.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/kohakuXLEpsilon_rev1.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/kohaku-xl-epsilon-rev3.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/kohaku-xl-zeta.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/nekorayxl_v06W3.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/CounterfeitXL-V1.0.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/ponyDiffusionV6XL_v6StartWithThisOne.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/Illustrious-XL-v0.1.safetensors", 1),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_earlyAccessVersion.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_epsilonPred05Version.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_epsilonPred075.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_epsilonPred077.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_epsilonPred10Version.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_epsilonPred11Version.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_vPredTestVersion.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_vPred05Version.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_vPred06Version.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_vPred065SVersion.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_vPred075SVersion.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_vPred09RVersion.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_vPred10Version.safetensors", 0),
("https://huggingface.co/licyk/sd-vae/resolve/main/sd_1.5/vae-ft-ema-560000-ema-pruned.safetensors", 0),
("https://huggingface.co/licyk/sd-vae/resolve/main/sd_1.5/vae-ft-mse-840000-ema-pruned.safetensors", 1),
("https://huggingface.co/licyk/sd-vae/resolve/main/sdxl_1.0/sdxl_fp16_fix_vae.safetensors", 1),
]
INSTALL_PARAMS = {
"torch_ver": TORCH_VER or None,
"xformers_ver": XFORMERS_VER or None,
"git_branch": SD_SCRIPTS_BRANCH or None,
"git_commit": SD_SCRIPTS_COMMIT or None,
"model_path": SD_MODEL_PATH or None,
"model_list": SD_MODEL,
"use_uv": USE_UV,
"pypi_index_mirror": PIP_INDEX_MIRROR or None,
"pypi_extra_index_mirror": PIP_EXTRA_INDEX_MIRROR or None,
"pytorch_mirror": PYTORCH_MIRROR or None,
"sd_scripts_repo": SD_SCRIPTS_REPO or None,
"sd_scripts_requirements": SD_SCRIPTS_REQUIREMENTS or None,
"retry": RETRY,
"huggingface_token": HF_TOKEN or None,
"modelscope_token": MS_TOKEN or None,
"wandb_token": WANDB_TOKEN or None,
"git_username": GIT_USER_NAME or None,
"git_email": GIT_USER_EMAIL or None,
"check_avaliable_gpu": CHECK_AVALIABLE_GPU,
"enable_tcmalloc": ENABLE_TCMALLOC,
"enable_cuda_malloc": ENABLE_CUDA_MALLOC,
"custom_sys_pkg_cmd": None,
"update_core": UPDATE_CORE,
}
HF_REPO_UPLOADER_PARAMS = {
"api_type": "huggingface",
"repo_id": HF_REPO_ID,
"repo_type": HF_REPO_TYPE,
"visibility": HF_REPO_VISIBILITY,
"upload_path": OUTPUT_PATH,
"retry": RETRY,
}
MS_REPO_UPLOADER_PARAMS = {
"api_type": "modelscope",
"repo_id": MS_REPO_ID,
"repo_type": MS_REPO_TYPE,
"visibility": MS_REPO_VISIBILITY,
"upload_path": OUTPUT_PATH,
"retry": RETRY,
}
os.makedirs(WORKSPACE, exist_ok=True)
os.makedirs(OUTPUT_PATH, exist_ok=True)
os.makedirs(INPUT_DATASET_PATH, exist_ok=True)
os.makedirs(SD_MODEL_PATH, exist_ok=True)
SD_SCRIPTS_PATH = os.path.join(WORKSPACE, WORKFOLDER)
logger.info("参数设置完成")
|
这个脚本参数一般就配置一次,后面再使用时就很少改动了。
在 SD Trainer Scripts Kaggle Jupyter NoteBook 中的使用方法
在 SD Trainer Scripts Kaggle Jupyter NoteBook 中,按照上面在 SD Scripts Kaggle Jupyter NoteBook 的方法修改配置后,完整的配置参数如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
|
WORKSPACE = "/kaggle"
WORKFOLDER = "sd-scripts"
USE_UV = True
USE_PYPI_MIRROR = False
PIP_INDEX_MIRROR = "https://pypi.python.org/simple"
PIP_EXTRA_INDEX_MIRROR = "https://download.pytorch.org/whl/cu124"
PIP_FIND_LINKS_MIRROR = "https://download.pytorch.org/whl/cu121/torch_stable.html"
USE_HF_MIRROR = False
HUGGINGFACE_MIRROR = "https://hf-mirror.com"
USE_GITHUB_MIRROR = False
CUSTOM_GITHUB_MIRROR = [
"https://ghfast.top/https://github.com",
"https://mirror.ghproxy.com/https://github.com",
"https://ghproxy.net/https://github.com",
"https://gh.api.99988866.xyz/https://github.com",
"https://gh-proxy.com/https://github.com",
"https://ghps.cc/https://github.com",
"https://gh.idayer.com/https://github.com",
"https://ghproxy.1888866.xyz/github.com",
"https://slink.ltd/https://github.com",
"https://github.boki.moe/github.com",
"https://github.moeyy.xyz/https://github.com",
"https://gh-proxy.net/https://github.com",
"https://gh-proxy.ygxz.in/https://github.com",
"https://wget.la/https://github.com",
"https://kkgithub.com",
"https://gitclone.com/github.com",
]
USE_CN_MODEL_MIRROR = False
CHECK_AVALIABLE_GPU = True
DOWNLOAD_THREAD = 16
ENABLE_TCMALLOC = True
ENABLE_CUDA_MALLOC = True
UPDATE_CORE = True
PYTORCH_DEVICE_TYPE = "auto"
TORCH_VER = ""
XFORMERS_VER = ""
INSTALL_BRANCH = "sd_scripts_dev"
USE_HF_TO_SAVE_MODEL = True
USE_MS_TO_SAVE_MODEL = True
HF_TOKEN = "hf_abcdef"
MS_TOKEN = "ms_fedcba"
HF_REPO_ID = "licyk/sd_training_model"
HF_REPO_TYPE = "model"
MS_REPO_ID = "licyks/sd_training_model"
MS_REPO_TYPE = "model"
HF_REPO_VISIBILITY = False
MS_REPO_VISIBILITY = False
GIT_USER_EMAIL = "username@example.com"
GIT_USER_NAME = "username"
LOG_MODULE = "tensorboard"
WANDB_TOKEN = ""
INPUT_DATASET_PATH = "/kaggle/dataset"
OUTPUT_PATH = "/kaggle/working/model"
SD_MODEL_PATH = "/kaggle/sd-models"
KAGGLE_INPUT_PATH = "/kaggle/input"
SD_MODEL = [
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/v1-5-pruned-emaonly.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/animefull-final-pruned.safetensors", 1),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/Counterfeit-V3.0_fp16.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/cetusMix_Whalefall2.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/cuteyukimixAdorable_neochapter3.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/ekmix-pastel-fp16-no-ema.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/ex2K_sse2.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/kohakuV5_rev2.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/meinamix_meinaV11.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/oukaStar_10.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/pastelMixStylizedAnime_pastelMixPrunedFP16.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/rabbit_v6.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/sweetSugarSyndrome_rev15.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/AnythingV5Ink_ink.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/bartstyledbBlueArchiveArtStyleFineTunedModel_v10.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/meinapastel_v6Pastel.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/qteamixQ_omegaFp16.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sd_1.5/tmndMix_tmndMixSPRAINBOW.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/sd_xl_base_1.0_0.9vae.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/animagine-xl-3.0.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/AnythingXL_xl.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/abyssorangeXLElse_v10.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/animaPencilXL_v200.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/animagine-xl-3.1.safetensors", 1),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/heartOfAppleXL_v20.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/baxlBartstylexlBlueArchiveFlatCelluloid_xlv1.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/kohaku-xl-delta-rev1.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/kohakuXLEpsilon_rev1.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/kohaku-xl-epsilon-rev3.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/kohaku-xl-zeta.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/nekorayxl_v06W3.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/CounterfeitXL-V1.0.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/ponyDiffusionV6XL_v6StartWithThisOne.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/Illustrious-XL-v0.1.safetensors", 1),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_earlyAccessVersion.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_epsilonPred05Version.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_epsilonPred075.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_epsilonPred077.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_epsilonPred10Version.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_epsilonPred11Version.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_vPredTestVersion.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_vPred05Version.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_vPred06Version.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_vPred065SVersion.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_vPred075SVersion.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_vPred09RVersion.safetensors", 0),
("https://huggingface.co/licyk/sd-model/resolve/main/sdxl_1.0/noobaiXLNAIXL_vPred10Version.safetensors", 0),
("https://huggingface.co/licyk/sd-vae/resolve/main/sd_1.5/vae-ft-ema-560000-ema-pruned.safetensors", 0),
("https://huggingface.co/licyk/sd-vae/resolve/main/sd_1.5/vae-ft-mse-840000-ema-pruned.safetensors", 1),
("https://huggingface.co/licyk/sd-vae/resolve/main/sdxl_1.0/sdxl_fp16_fix_vae.safetensors", 1),
]
if PYTORCH_DEVICE_TYPE == "auto":
PYTORCH_DEVICE_TYPE = None
INSTALL_PARAMS = {
"pytorch_mirror_type": PYTORCH_DEVICE_TYPE,
"custom_pytorch_package": TORCH_VER or None,
"custom_xformers_package": XFORMERS_VER or None,
"use_pypi_mirror": USE_PYPI_MIRROR,
"use_uv": USE_UV,
"use_github_mirror": USE_GITHUB_MIRROR,
"custom_github_mirror": CUSTOM_GITHUB_MIRROR or None,
"install_branch": INSTALL_BRANCH or None,
"no_pre_download_model": True,
"use_cn_model_mirror": USE_CN_MODEL_MIRROR,
"use_hf_mirror": USE_HF_MIRROR,
"model_path": SD_MODEL_PATH or None,
"model_list": SD_MODEL or None,
"pypi_index_mirror": PIP_INDEX_MIRROR or None,
"pypi_extra_index_mirror": PIP_EXTRA_INDEX_MIRROR or None,
"pypi_find_links_mirror": PIP_FIND_LINKS_MIRROR or None,
"github_mirror": CUSTOM_GITHUB_MIRROR or None,
"huggingface_mirror": HUGGINGFACE_MIRROR or None,
"huggingface_token": HF_TOKEN or None,
"modelscope_token": MS_TOKEN or None,
"wandb_token": WANDB_TOKEN or None,
"git_username": GIT_USER_NAME or None,
"git_email": GIT_USER_EMAIL or None,
"check_avaliable_gpu": CHECK_AVALIABLE_GPU,
"enable_tcmalloc": ENABLE_TCMALLOC,
"enable_cuda_malloc": ENABLE_CUDA_MALLOC,
"custom_sys_pkg_cmd": None if sys.platform == "linux" and shutil.which("apt") else [],
"update_core": UPDATE_CORE,
}
HF_REPO_UPLOADER_PARAMS = {
"api_type": "huggingface",
"repo_id": HF_REPO_ID,
"repo_type": HF_REPO_TYPE,
"visibility": HF_REPO_VISIBILITY,
"upload_path": OUTPUT_PATH,
}
MS_REPO_UPLOADER_PARAMS = {
"api_type": "modelscope",
"repo_id": MS_REPO_ID,
"repo_type": MS_REPO_TYPE,
"visibility": MS_REPO_VISIBILITY,
"upload_path": OUTPUT_PATH,
}
os.makedirs(WORKSPACE, exist_ok=True)
os.makedirs(OUTPUT_PATH, exist_ok=True)
os.makedirs(INPUT_DATASET_PATH, exist_ok=True)
os.makedirs(SD_MODEL_PATH, exist_ok=True)
SD_SCRIPTS_PATH = os.path.join(WORKSPACE, WORKFOLDER)
logger.info("参数设置完成")
|
7. 自定义模型上传
训练脚本提供的模型可能不适合自己的训练要求,此时可以上传自己所需的模型。比如我需要上传ill-xl.safetensors这个模型,下面提供了 3 种方式进行模型上传。
在右侧的 Kaggle Input(Kaggle 导入工具)支持上传自己的模型到 Kaggle 中,在 Notebook(笔记本)-> Input(导入)-> Upload(上传)-> New Model(新建模型),在模型上传界面选择要上传的模型,此时将弹出模型信息设置界面。MODEL NAME(模型名称)填写模型的名称,这将决定模型所在的文件夹名称,这里我设置成ill-xl-01,FRAMEWORK(框架)选择 Other,LICENSE(许可证)选择 Unknown,如果还有其他需要上传的模型,可以在下方继续选择模型,配置完成后点击 Create(创建)上传模型。

根据刚刚设置的 MODEL NAME(模型名称),上传的ill-xl.safetensors模型将会在{INPUT_DATASET_PATH}/ill-xl-01/ill-xl.safetensors,即/kaggle/dataset/ill-xl-01/ill-xl.safetensors。
7.2 使用模型下载链接上传模型
除了可以使用 Kaggle Input(Kaggle 导入工具)上传模型,还可以将模型上传到模型托管平台,获取模型下载链接后使用下载链接将模型下载到 Kaggle 中。
刚刚在 ModelScope 上创建了一个模型仓库,并将ill-xl.safetensors上传到该仓库中。
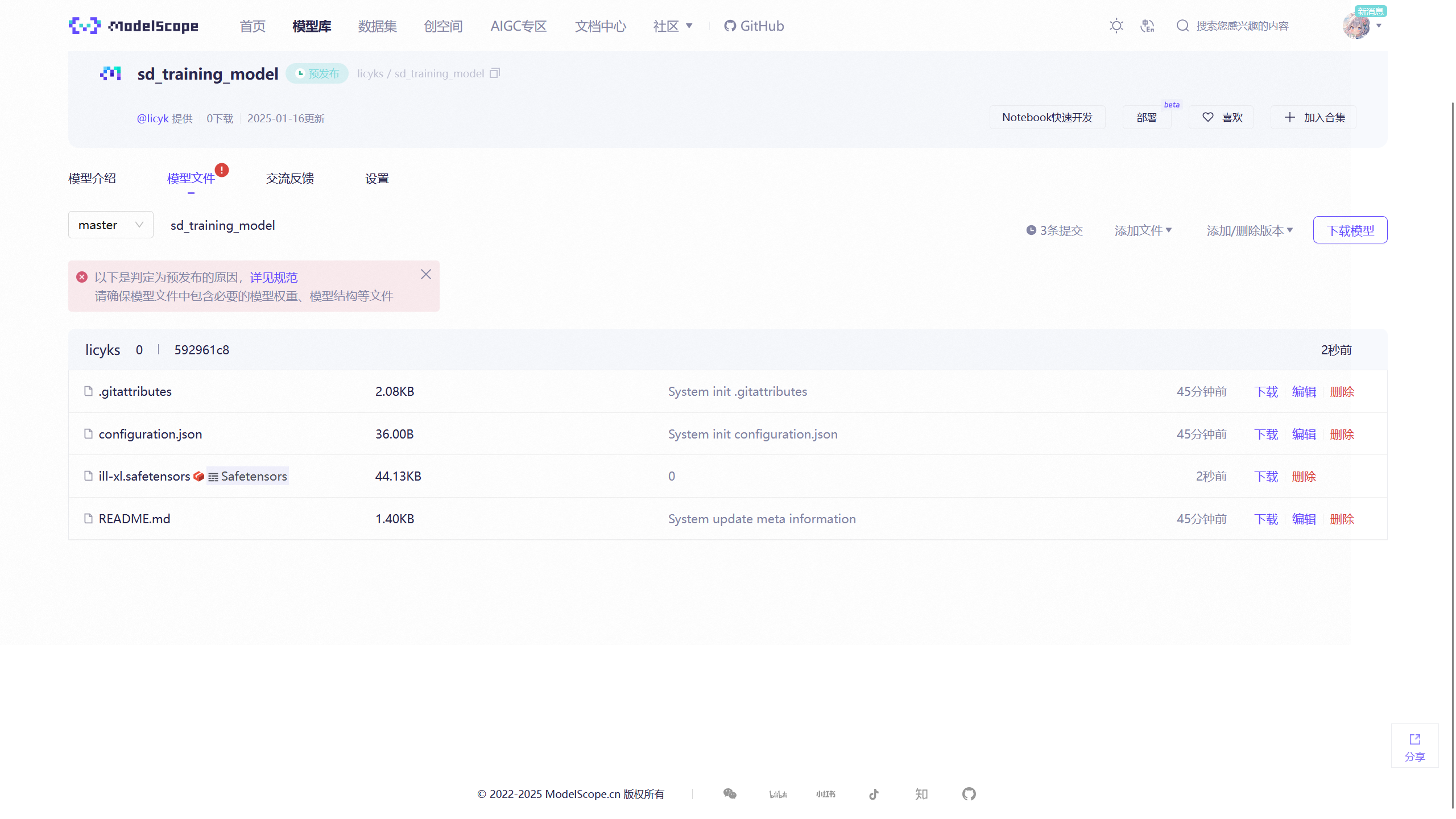
右键下载按钮后获取到下载链接,比如https://modelscope.cn/models/licyks/sd_training_model/resolve/master/ill-xl.safetensors。
得到模型下载链接后,可以通过sd_scripts.get_model()函数将模型下载到 Kaggle 中。在安装单元中有注释说明了该函数的用法,根据注释的说明进行修改。
1
2
3
4
5
| sd_scripts.get_model(
url="https://modelscope.cn/models/licyks/sd_training_model/resolve/master/ill-xl.safetensors",
path=SD_MODEL_PATH,
filename="ill-xl.safetensors",
)
|
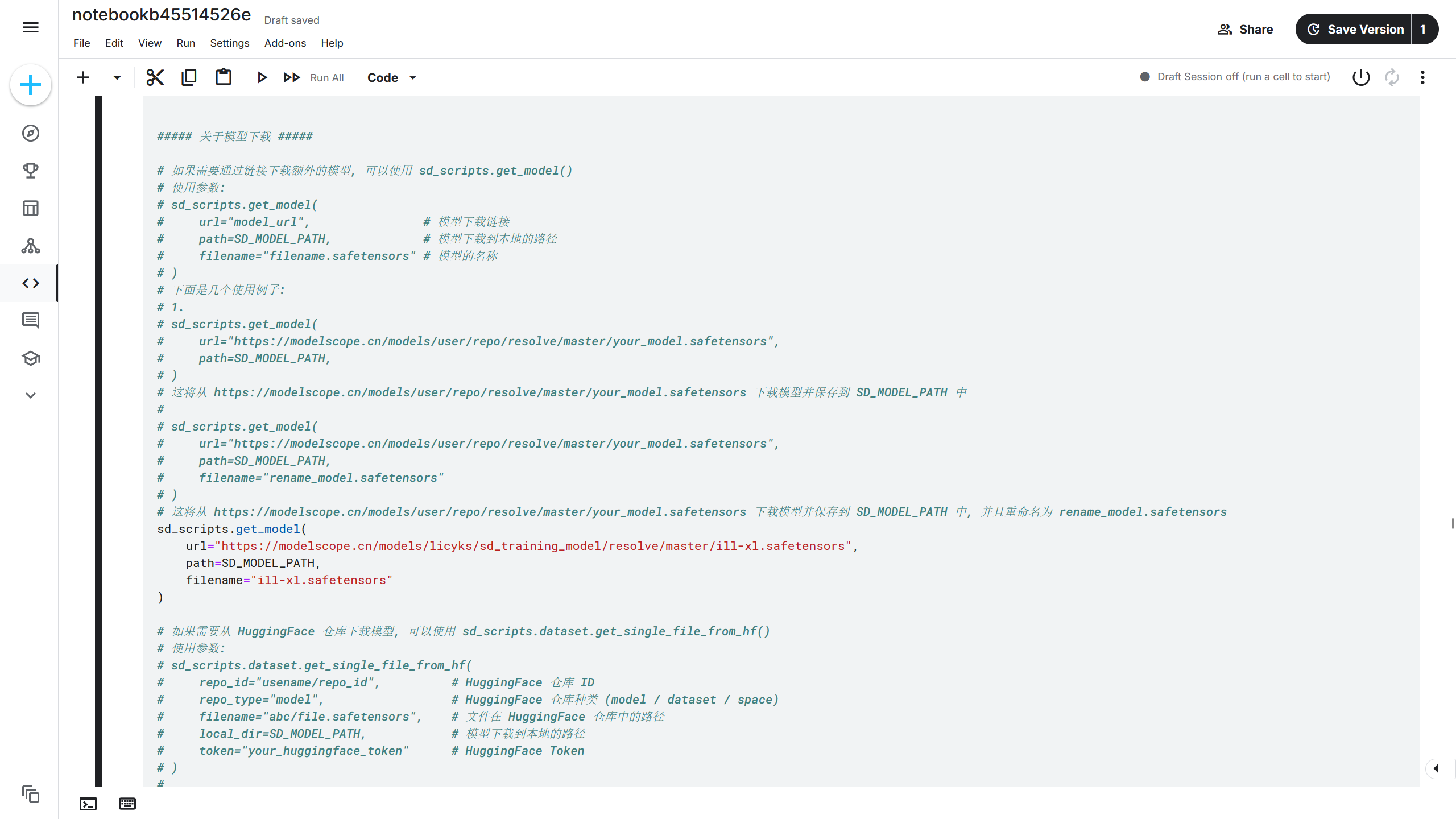
该模型下载到{SD_MODEL_PATH}/ill-xl.safetensors,即/kaggle/sd-models/ill-xl.safetensors。
在 SD Trainer Scripts Kaggle Jupyter NoteBook 中的使用方法
在 SD Trainer Scripts Kaggle Jupyter NoteBook 中,使用的下载函数为sd_trainer_scripts.get_model(),按照上面在 SD Scripts Kaggle Jupyter NoteBook 的方法修改后,调用函数代码如下:
1
2
3
4
5
| sd_trainer_scripts.get_model(
url="https://modelscope.cn/models/licyks/sd_training_model/resolve/master/ill-xl.safetensors",
path=SD_MODEL_PATH,
filename="ill-xl.safetensors",
)
|
7.3 使用 HuggingFace 上传模型
如果将文件保存到 HuggingFace,比如将ill-xl.safetensors上传到刚刚在 HuggingFace 上创建的模型仓库。
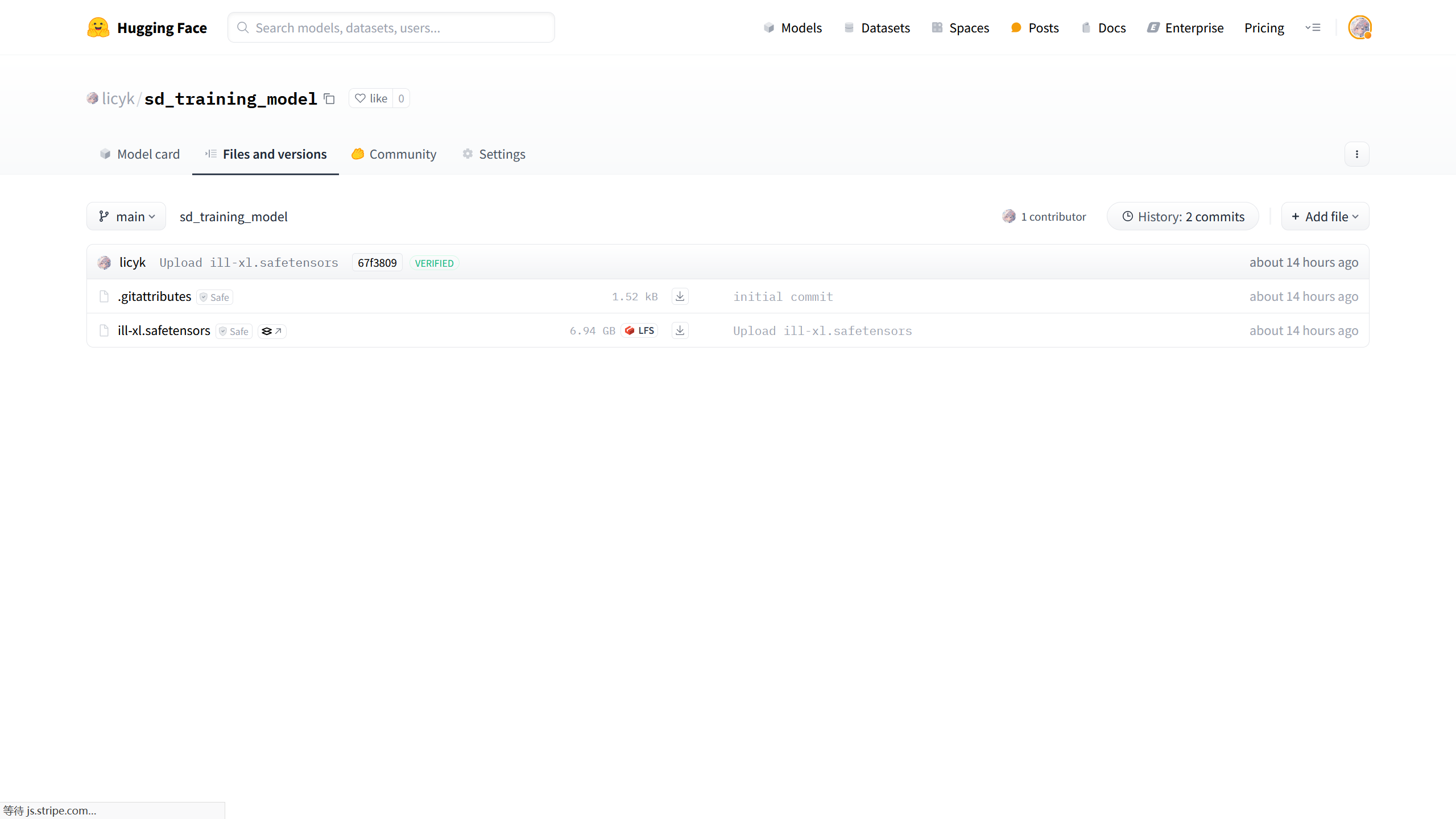
在 HuggingFace 上可以获取文件的下载链接,使用上面的方法将模型下载到 Kaggle 中,也可以使用sd_scripts.repo.download_files_from_repo()函数下载到 kaggle 中。在安装单元中有注释说明了该函数的用法,根据注释的说明进行修改。
1
2
3
4
5
6
7
| sd_scripts.repo.download_files_from_repo(
api_type="huggingface",
repo_id="licyk/sd_training_model",
repo_type="model",
folder="ill-xl.safetensors",
local_dir=SD_MODEL_PATH,
)
|
如果刚刚的模型仓库为私有仓库,则需要 HuggingFace Token 进行访问,不过在前面的步骤就配置好了,所以不需要担心这个问题。
模型将会下载到{SD_MODEL_PATH}/ill-xl.safetensors,即/kaggle/sd-models/ill-xl.safetensors。
在 SD Trainer Scripts Kaggle Jupyter NoteBook 中的使用方法
在 SD Trainer Scripts Kaggle Jupyter NoteBook 中,使用的下载函数为sd_trainer_scripts.download_files_from_repo(),按照上面在 SD Scripts Kaggle Jupyter NoteBook 的方法修改后,调用函数代码如下:
1
2
3
4
5
6
7
| sd_trainer_scripts.download_files_from_repo(
api_type="huggingface",
repo_id="licyk/sd_training_model",
repo_type="model",
folder="ill-xl.safetensors",
local_dir=SD_MODEL_PATH,
)
|
详解下载函数的功能
sd_scripts.repo.download_files_from_repo()这个函数不仅可以用于下载模型,也可以用于下载训练集,并且可以用在 HuggingFace 仓库和 ModelScope 仓库上,所以这里详细讲一下这个函数的使用。
下面是这个函数的所有参数:
1
2
3
4
5
6
7
8
9
| sd_scripts.repo.download_files_from_repo(
api_type="huggingface",
local_dir=SD_MODEL_PATH,
repo_id="usename/repo_id",
repo_type="model",
folder="path/in/repo/file.safetensors",
retry=RETRY,
num_threads=DOWNLOAD_THREAD,
)
|
标注为可选参数的参数可省略,省略时则使用该参数的默认值。而其他参数就不能被省略,必须给定一个值。
api_type参数用于指定是从哪个仓库进行模型下载,如果需要从 HuggingFace 仓库下载文件,则指定huggingface;如果是从 ModelScope 仓库下载文件,则指定modelscope。
local_dir指定将仓库的文件下载到本地的路径,这里也指的是下载到 Kaggle 服务器中的路径。在 Kaggle 的训练脚本中指定了SD_MODEL_PATH变量存储模型的路径,INPUT_DATASET_PATH变量存储训练集的路径,所以直接使用其中一个变量作为这个参数的值就行了。
repo_id指定的是仓库的 ID,要从哪个仓库下载文件就填那个仓库的 ID。
repo_type指定的是仓库的类型,虽然是可选参数,但是不推荐省略。比如要从 dataset 类型的仓库下载文件,如果不指定这个参数时,该参数就默认是 model,就会去找 model 类型的仓库尝试去下载文件,最终导致下载失败。
retry和num_threads分别指定下载失败时重试的次数和下载的线程数,这两个参数都是可选参数,所以填不填影响都不是很大。
folder参数为可选参数,当不填写时,则下载整个仓库中的所有文件,填写后就指定下载文件,这里就举个例子。
比如这是一个仓库的文件树,表示仓库中有什么文件和路径在哪:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| 仓库
├── character_aaaki
│ ├── 1_aaaki
│ │ ├── 1.png
│ │ ├── 1.txt
│ │ ├── 3.png
│ │ └── 3.txt
│ └── 2_aaaki
│ ├── 4.png
│ └── 4.txt
├── character_robin
│ └── 1_xxx
│ ├── 11.png
│ └── 11.txt
├── style_pvc
│ └── 5_aaa
│ ├── test.png
│ └── test.txt
├── ill-xl.safetensors
└── other
└── noob_xl_vpre.safetensors
|
比如想要下载other/noob_xl_vpre.safetensors这个路径的文件,则folder="other/noob_xl_vpre.safetensors",此时将下载 noob_xl_vpre.safetensors 这个文件。
如果想要下载的是一个文件夹,比如character_aaaki这个文件夹,则folder="character_aaaki",这样 character_aaaki 文件夹中的所有文件都会被下载。
从这两个例子可以知道folder参数是通过前缀匹配选择要下载的文件的。
那么下载后文件保存在哪呢?这就由local_dir参数和文件在仓库中的路径决定了,local_dir参数的路径拼接上文件在仓库中的路径就得到这个文件的实际路径了。
比如local_dir指定的是/kaggle/model这个路径,对于刚刚的 noob_xl_vpre.safetensors 文件,文件在仓库的路径是other/noob_xl_vpre.safetensors,则最终的文件保存路径就在/kaggle/model/other/noob_xl_vpre.safetensors;如果是刚刚的character_aaaki文件夹,最终的保存路径就在/kaggle/model/character_aaaki,这个 character_aaaki 文件夹中有个 1.png 文件,根据刚刚的仓库的文件树就可以知道最终保存在本地的路径在/kaggle/model/character_aaaki/1_aaaki/1.png。
在 SD Trainer Scripts Kaggle Jupyter NoteBook 中的使用方法
在 SD Trainer Scripts Kaggle Jupyter NoteBook 中,使用的下载函数为sd_trainer_scripts.download_files_from_repo(),函数可选的参数如下:
1
2
3
4
5
6
7
8
| sd_trainer_scripts.download_files_from_repo(
api_type="huggingface",
local_dir=SD_MODEL_PATH,
repo_id="usename/repo_id",
repo_type="model",
folder="path/in/repo/file.safetensors",
num_threads=DOWNLOAD_THREAD,
)
|
和 SD Scripts Kaggle Jupyter NoteBook 中sd_scripts.repo.download_files_from_repo()函数的使用方法类似,但是移除了retry参数。
7.4 使用 ModelScope 上传模型
如果将文件保存到 ModelScope,比如将ill-xl.safetensors上传到刚刚在 ModelScope 上创建的模型仓库,可以使用sd_scripts.repo.download_files_from_repo()函数进行下载,注意要把api_type的值修改成modelscope,这样才能从 ModelScope 下载模型。
1
2
3
4
5
6
7
| sd_scripts.repo.download_files_from_repo(
api_type="modelscope",
repo_id="licyks/sd_training_model",
repo_type="model",
folder="ill-xl.safetensors",
local_dir=SD_MODEL_PATH,
)
|
使用方法参考7.3 使用 HuggingFace 上传模型部分的说明就好了,毕竟用的都是同一个sd_scripts.repo.download_files_from_repo()函数呢。
在 SD Trainer Scripts Kaggle Jupyter NoteBook 中的使用方法
在 SD Trainer Scripts Kaggle Jupyter NoteBook 中,使用的下载函数为sd_trainer_scripts.download_files_from_repo(),按照上面在 SD Scripts Kaggle Jupyter NoteBook 的方法修改后,调用函数代码如下:
1
2
3
4
5
6
7
| sd_trainer_scripts.download_files_from_repo(
api_type="modelscope",
repo_id="licyks/sd_training_model",
repo_type="model",
folder="ill-xl.safetensors",
local_dir=SD_MODEL_PATH,
)
|
8. 训练集上传
有了训练所需的模型之后,还需要上传训练集作为训练素材,下面提供 3 种方式上传训练集。
在右侧的 Kaggle Input(Kaggle 导入工具)支持上传自己的训练集到 Kaggle 中,在 Notebook(笔记本)-> Input(导入)-> Upload(上传)-> New Dataset(新建数据集),在训练集上传界面选择自己的训练集文件夹,比如前面创建的character_aaaki文件夹,在 DATASET TITLE(数据集名称)填写训练集的名字,这里我填的是ch-aaaki,再点击 Create(创建)上传训练集。
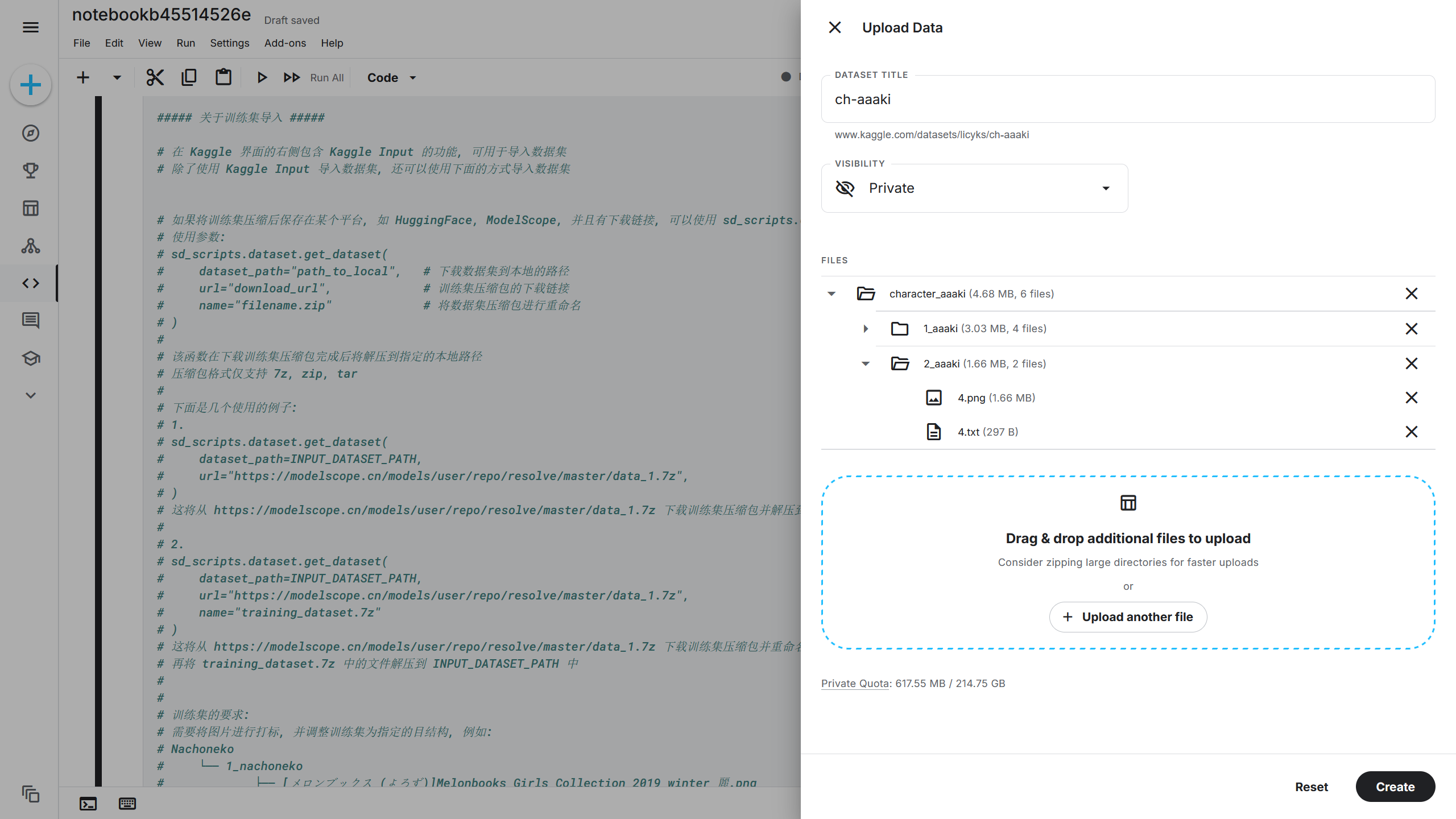
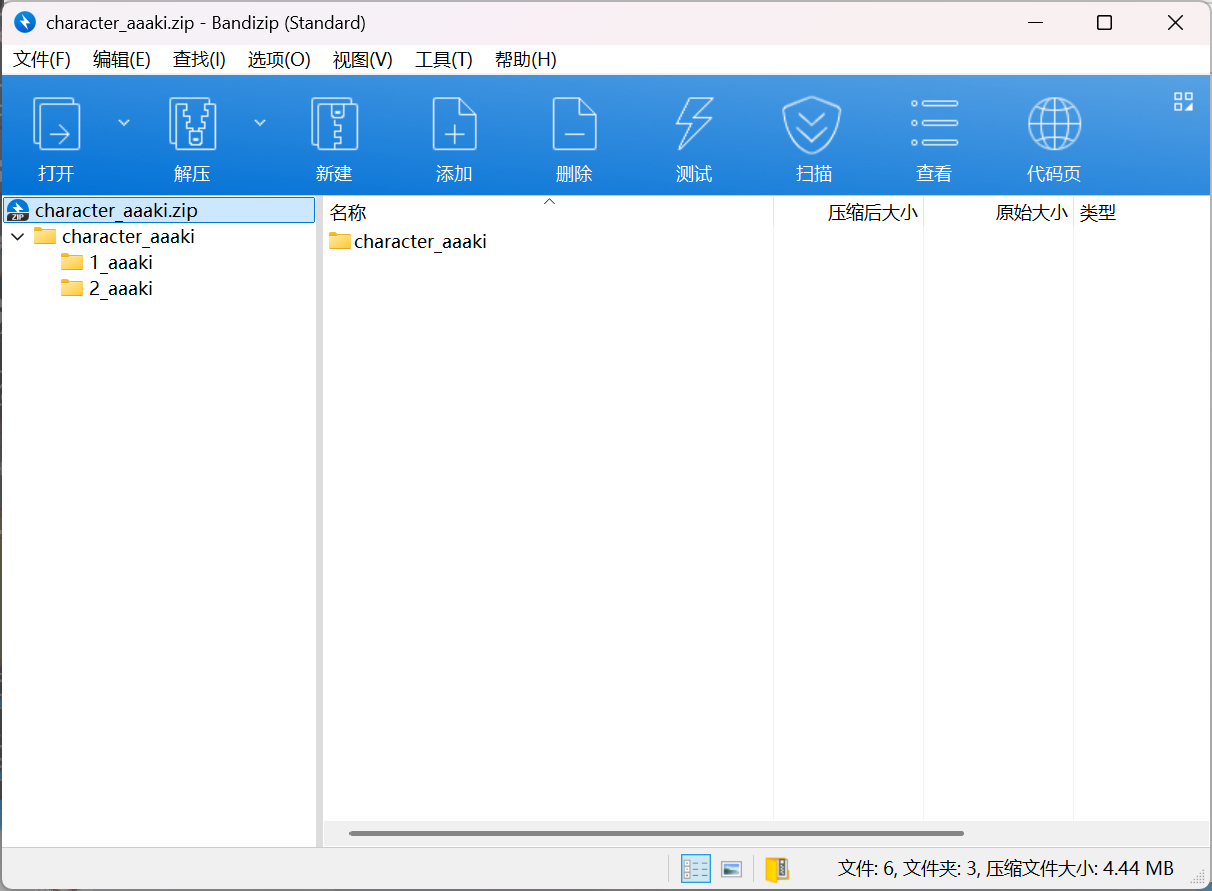
如果为了加快上传速度,可以将训练集文件夹压缩成 ZIP 文件再上传。
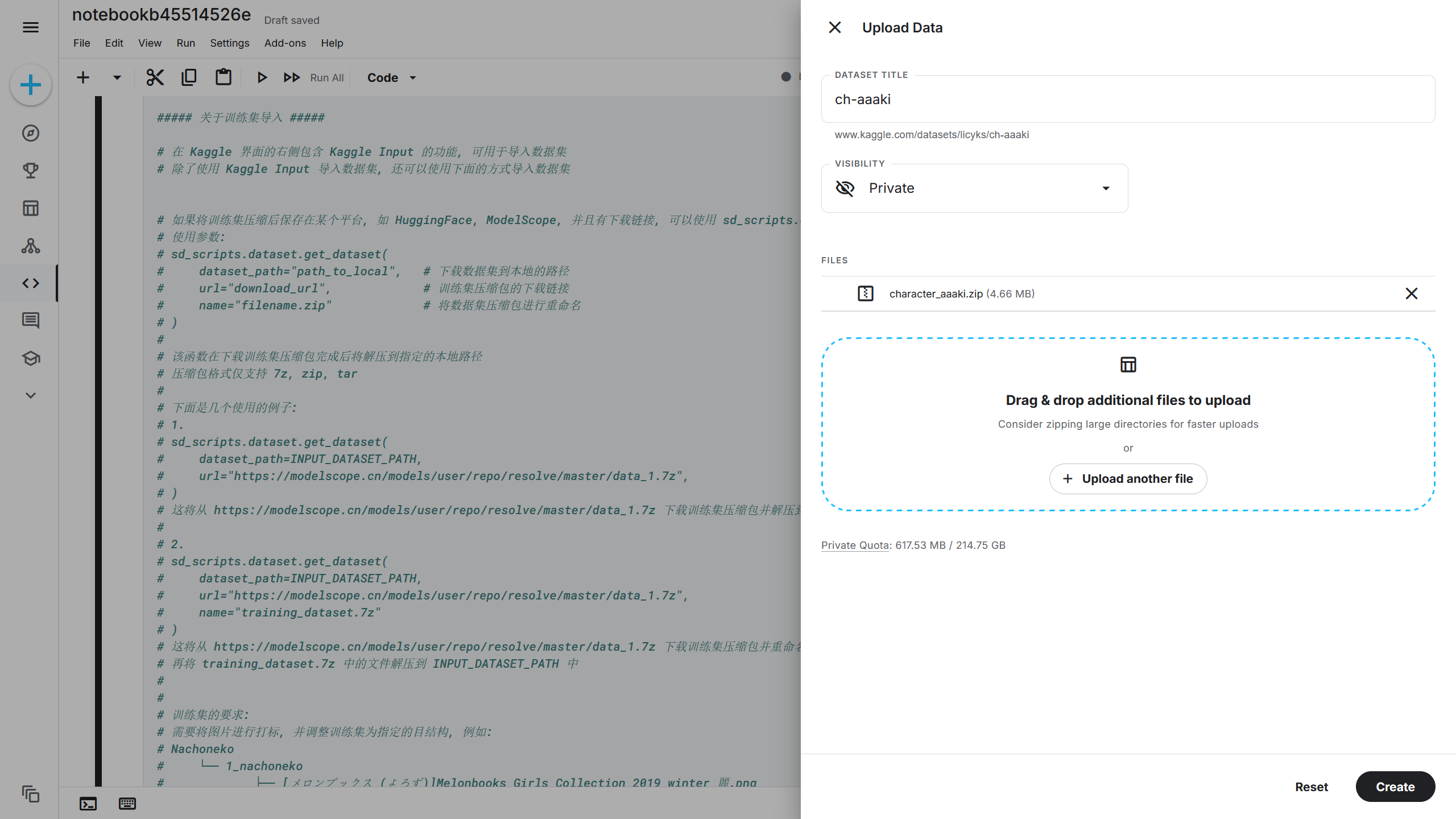
根据刚刚设置的 DATASET TITLE(数据集名称),训练集将上传到{INPUT_DATASET_PATH}/ch-aaaki/character_aaaki,即/kaggle/dataset/ch-aaaki/character_aaaki。
8.2 使用训练集下载链接上传训练集
除了可以使用 Kaggle Input(Kaggle 导入工具)上传训练集,还可以将训练集进行压缩,上传训练集压缩包到模型托管平台,获取训练集下载链接后使用下载链接将训练集下载到 Kaggle 中。
将训练集使用 ZIP / 7Z / TAR 格式进行压缩后,利用之前在 ModelScope 上创建的仓库上传训练集压缩包。
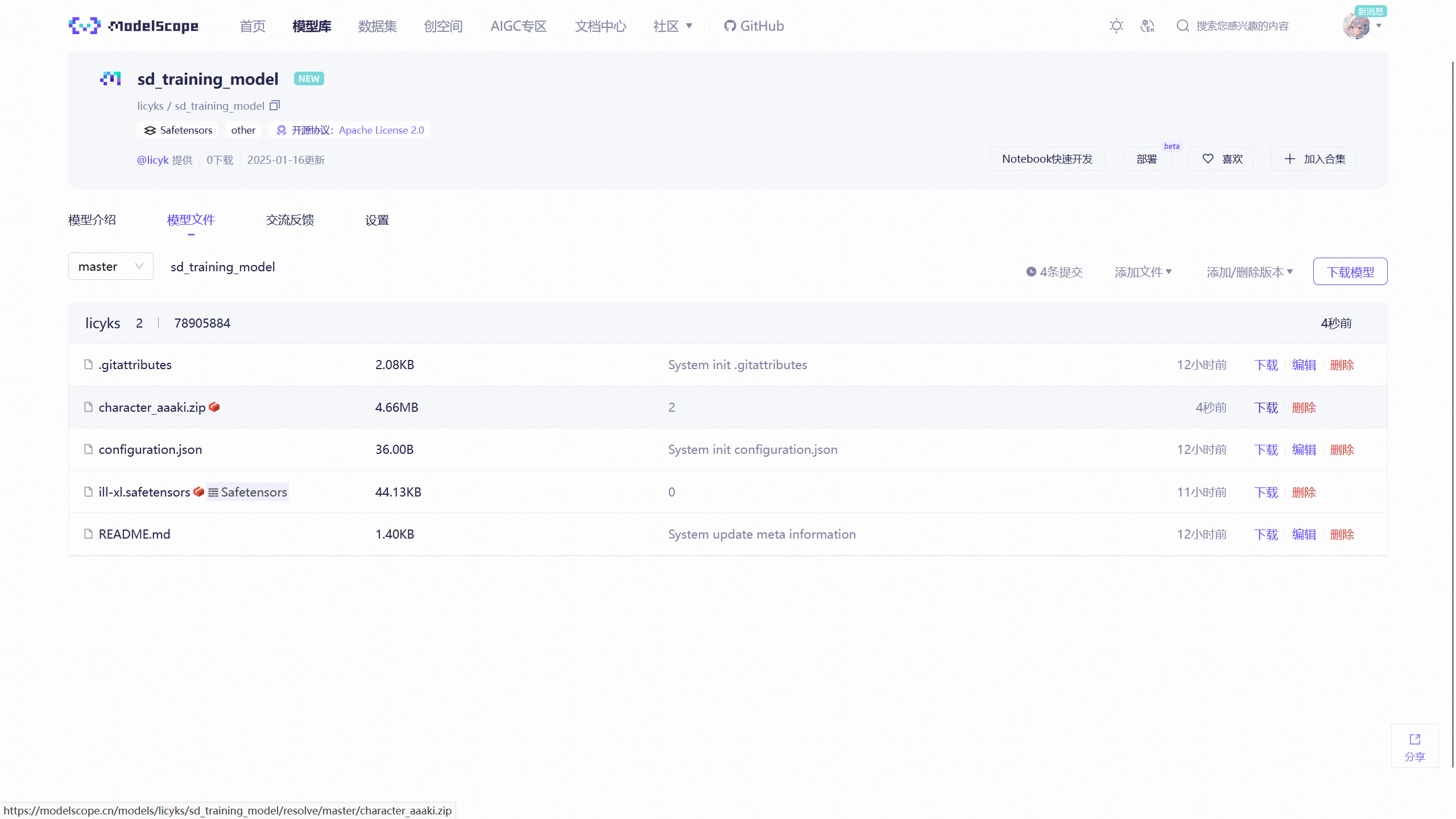
右键下载按钮后获取到下载链接,比如https://modelscope.cn/models/licyks/sd_training_model/resolve/master/character_aaaki.zip。
得到训练集下载链接后,可以通过sd_scripts.download_archive_and_unpack()函数将训练集下载到 Kaggle 中。在安装单元中有注释说明了该函数的用法,根据注释的说明进行修改。
1
2
3
4
5
| sd_scripts.download_archive_and_unpack(
local_dir=INPUT_DATASET_PATH,
url="https://modelscope.cn/models/licyks/sd_training_model/resolve/master/character_aaaki.zip",
name="character_aaaki.zip",
)
|
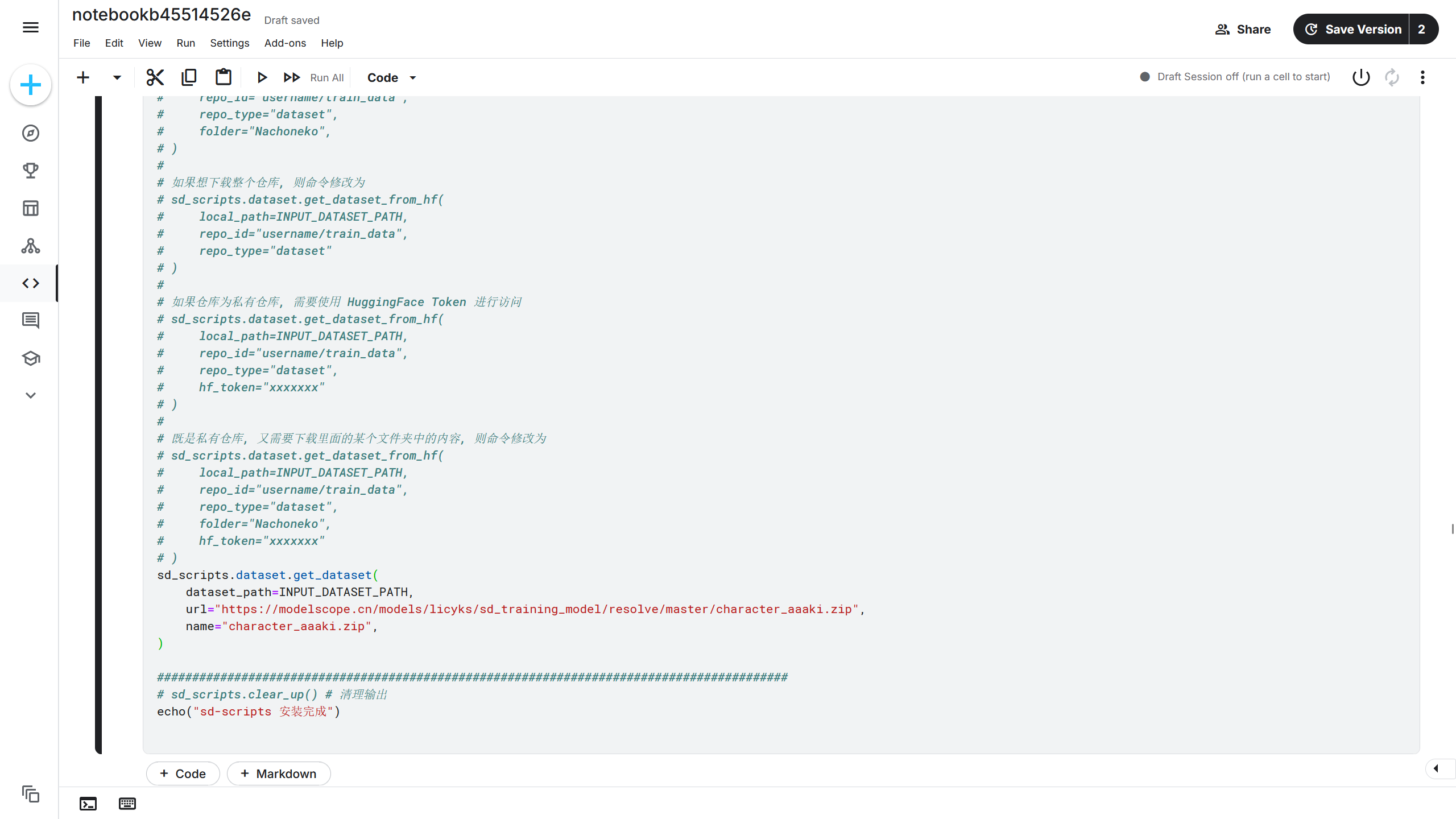
该训练集将会下载并解压到{INPUT_DATASET_PATH}中,即/kaggle/dataset,解压出来的文件夹名称为character_aaaki(和压缩character_aaaki这个文件夹时处理方式有关),则该训练集的完整路径为/kaggle/dataset/character_aaaki。
8.3 使用 HuggingFace 上传训练集
如果将训练集保存到 HuggingFace,比如在 HuggingFace 上创建一个训练集仓库,将character_aaaki这个文件夹上传到刚创建的训练集仓库。
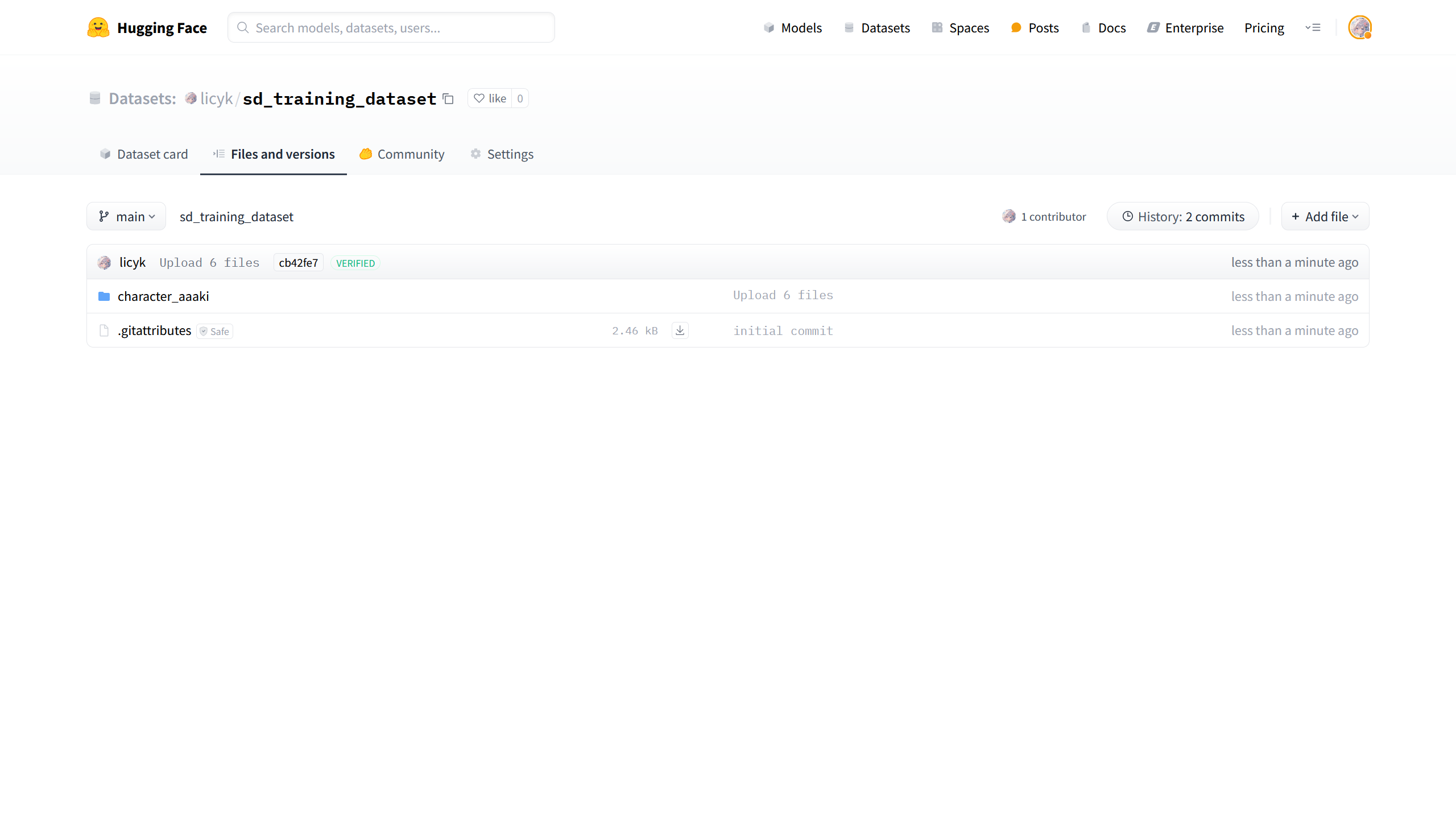
再使用sd_scripts.repo.download_files_from_repo()函数将训练集下载到 Kaggle 中。在安装单元中有注释说明了该函数的用法,根据注释的说明进行修改,详细的使用方法就参考7.3 使用 HuggingFace 上传模型部分的内容就好了。
1
2
3
4
5
6
7
| sd_scripts.repo.download_files_from_repo(
api_type="huggingface",
local_dir=INPUT_DATASET_PATH,
repo_id="licyk/sd_training_dataset",
repo_type="dataset",
folder="character_aaaki",
)
|
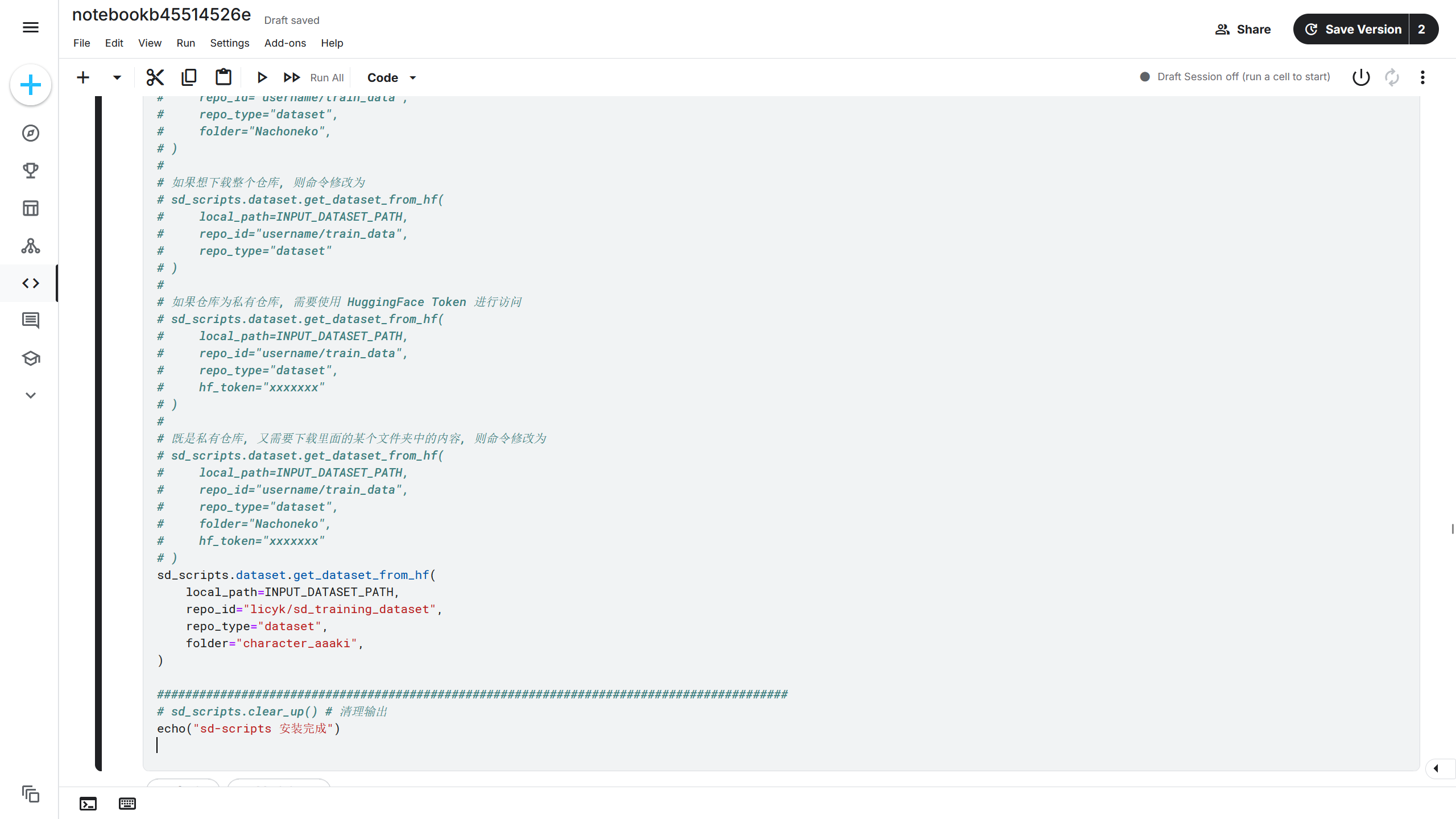
训练集将会下载到{INPUT_DATASET_PATH}中,即/kaggle/dataset,文件夹名称为character_aaaki(下载训练集的时候会保持和在 HuggingFace 中一样的目录结构),则该训练集的完整路径为/kaggle/dataset/character_aaaki。
在 SD Trainer Scripts Kaggle Jupyter NoteBook 中的使用方法
在 SD Trainer Scripts Kaggle Jupyter NoteBook 中,使用的下载函数为sd_trainer_scripts.download_files_from_repo(),按照上面在 SD Scripts Kaggle Jupyter NoteBook 的方法修改后,调用函数代码如下:
1
2
3
4
5
6
7
| sd_trainer_scripts.download_files_from_repo(
api_type="huggingface",
local_dir=INPUT_DATASET_PATH,
repo_id="licyk/sd_training_dataset",
repo_type="dataset",
folder="character_aaaki",
)
|
构建训练集小技巧
前面的 character_aaaki 训练集上传到 HuggingFace 上时结构如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| HuggingFace_Repo (licyk/sd_training_dataset)
├── character_aaaki
│ ├── 1_aaaki
│ │ ├── 1.png
│ │ ├── 1.txt
│ │ ├── 3.png
│ │ └── 3.txt
│ └── 2_aaaki
│ ├── 4.png
│ └── 4.txt
├── character_robin
│ └── 1_xxx
│ ├── 11.png
│ └── 11.txt
└── style_pvc
└── 5_aaa
├── test.png
└── test.txt
|
可能有时候不想为训练集中每个子训练集设置不同的重复次数,又不想上传的时候再多套一层文件夹,就把训练集结构调整成了下面的(我自己经常这样做):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| HuggingFace_Repo (licyk/sd_training_dataset)
├── character_aaaki
│ ├── 1.png
│ ├── 1.txt
│ ├── 3.png
│ ├── 3.txt
│ ├── 4.png
│ └── 4.txt
├── character_robin
│ └── 1_xxx
│ ├── 11.png
│ └── 11.txt
└── style_pvc
└── 5_aaa
├── test.png
└── test.txt
|
此时这个状态的训练集是缺少子训练集和重复次数的,如果直接使用sd_scripts.repo.download_files_from_repo()去下载训练集并用于训练将会导致报错。不过没关系,可以自己再编写一个函数对sd_scripts.repo.download_files_from_repo()函数再次封装,自动加上子训练集并设置重复次数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| def make_dataset(
local_dir: str,
repo_id: str,
repo_type: str,
repeat: int,
folder: str,
) -> None:
import os
import shutil
origin_dataset_path = os.path.join(local_dir, folder)
tmp_dataset_path = os.path.join(local_dir, f"{repeat}_{folder}")
new_dataset_path = os.path.join(origin_dataset_path, f"{repeat}_{folder}")
sd_scripts.repo.download_files_from_repo(
api_type="huggingface",
local_dir=local_dir,
repo_id=repo_id,
repo_type=repo_type,
folder=folder,
)
if os.path.exists(origin_dataset_path):
logger.info("设置 %s 训练集的重复次数为 %s", folder, repeat)
shutil.move(origin_dataset_path, tmp_dataset_path)
shutil.move(tmp_dataset_path, new_dataset_path)
else:
logger.error("从 %s 下载 %s 失败", repo_id, folder)
|
编写好后,可以去调用这个函数了。
1
2
3
4
5
6
7
| make_dataset(
local_dir=INPUT_DATASET_PATH,
repo_id="licyk/sd_training_dataset",
repo_type="dataset",
repeat=3,
folder="character_aaaki",
)
|
该函数将会把character_aaaki训练集下载到{INPUT_DATASET_PATH}中,即/kaggle/dataset,文件夹名称为character_aaaki,并且character_aaaki文件夹内继续创建了一个子文件夹作为子训练集,根据repeat=3将子训练集的重复次数设置为 3。
注意,如果是在 SD Trainer Scripts Kaggle Jupyter NoteBook 中使用,需要将 sd_scripts.repo.download_files_from_repo 替换为 sd_trainer_scripts.download_files_from_repo 。
8.4 使用 ModelScope 上传训练集
如果将训练集保存到 HuggingFace,比如在 HuggingFace 上创建一个训练集仓库,将character_aaaki这个文件夹上传到刚创建的训练集仓库。
再使用sd_scripts.repo.download_files_from_repo()函数将训练集下载到 Kaggle 中。在安装单元中有注释说明了该函数的用法,根据注释的说明进行修改,这个函数讲得也多了,详细的使用方法看7.3 使用 HuggingFace 上传模型的部分就好了。
1
2
3
4
5
6
7
| sd_scripts.repo.download_files_from_repo(
api_type="modelscope",
local_dir=INPUT_DATASET_PATH,
repo_id="licyks/sd_training_dataset",
repo_type="dataset",
folder="character_aaaki",
)
|
在 SD Trainer Scripts Kaggle Jupyter NoteBook 中的使用方法
在 SD Trainer Scripts Kaggle Jupyter NoteBook 中,使用的下载函数为sd_trainer_scripts.download_files_from_repo(),按照上面在 SD Scripts Kaggle Jupyter NoteBook 的方法修改后,调用函数代码如下:
1
2
3
4
5
6
7
| sd_trainer_scripts.download_files_from_repo(
api_type="modelscope",
local_dir=INPUT_DATASET_PATH,
repo_id="licyks/sd_training_dataset",
repo_type="dataset",
folder="character_aaaki",
)
|
9. 编写训练参数
有了模型和训练集,此时就可以编写模型训练参数进行模型训练了,在模型训练单元中编写训练训练命令。
因为篇幅问题,这里就不涉及大量的训练参数说明,直接使用已有训练参数模板,在已有的训练参数上进行修改。
这些可用的参数可通过加上-h参数后运行来查看。
下面是我比较常用的训练参数,可以自行在这些模板中寻找。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
|
|
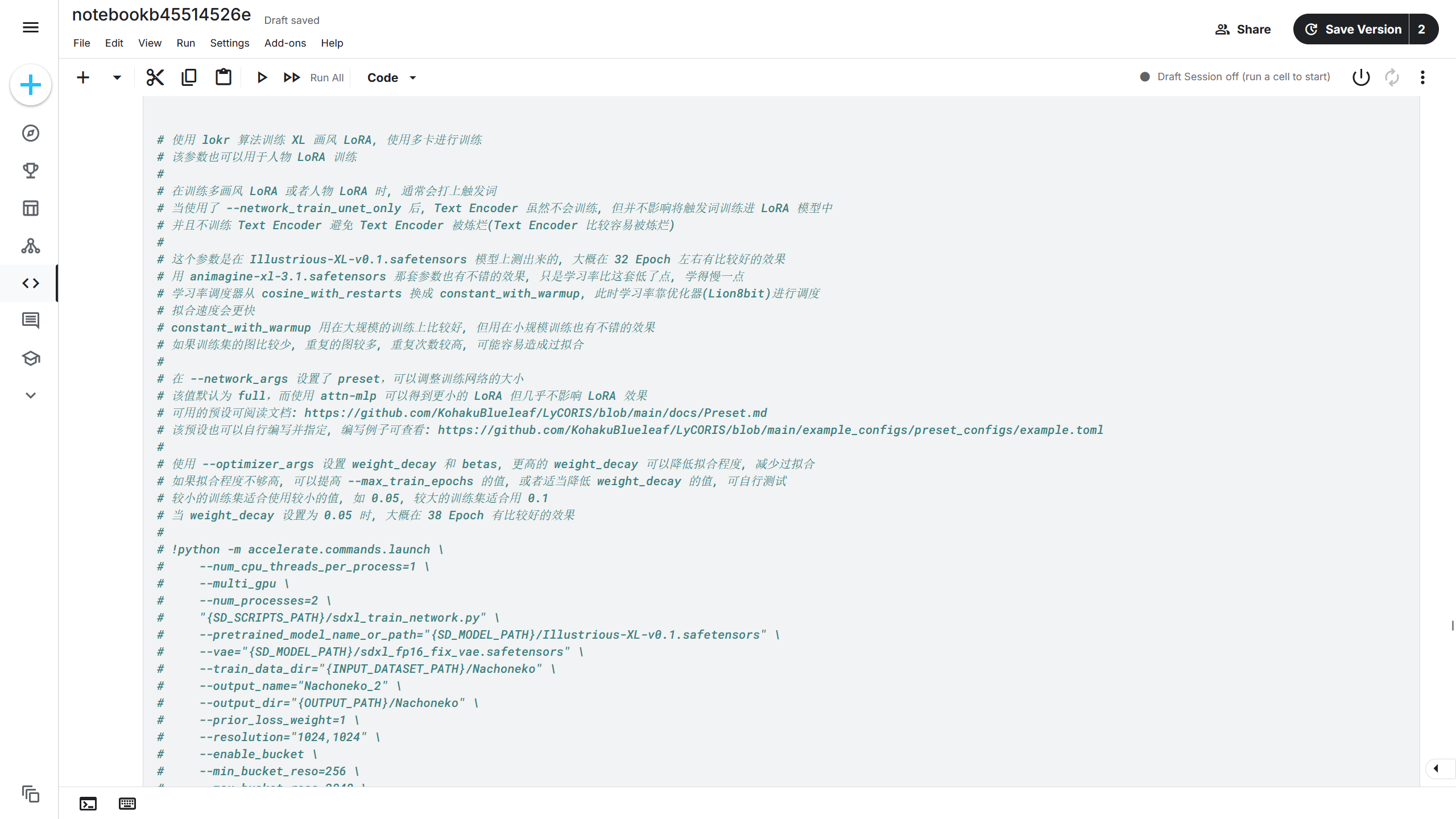
在该训练命令中,前面使用了#进行注释,此时需要将这些注释取消掉使其能够被执行,使用鼠标选中这些命令。
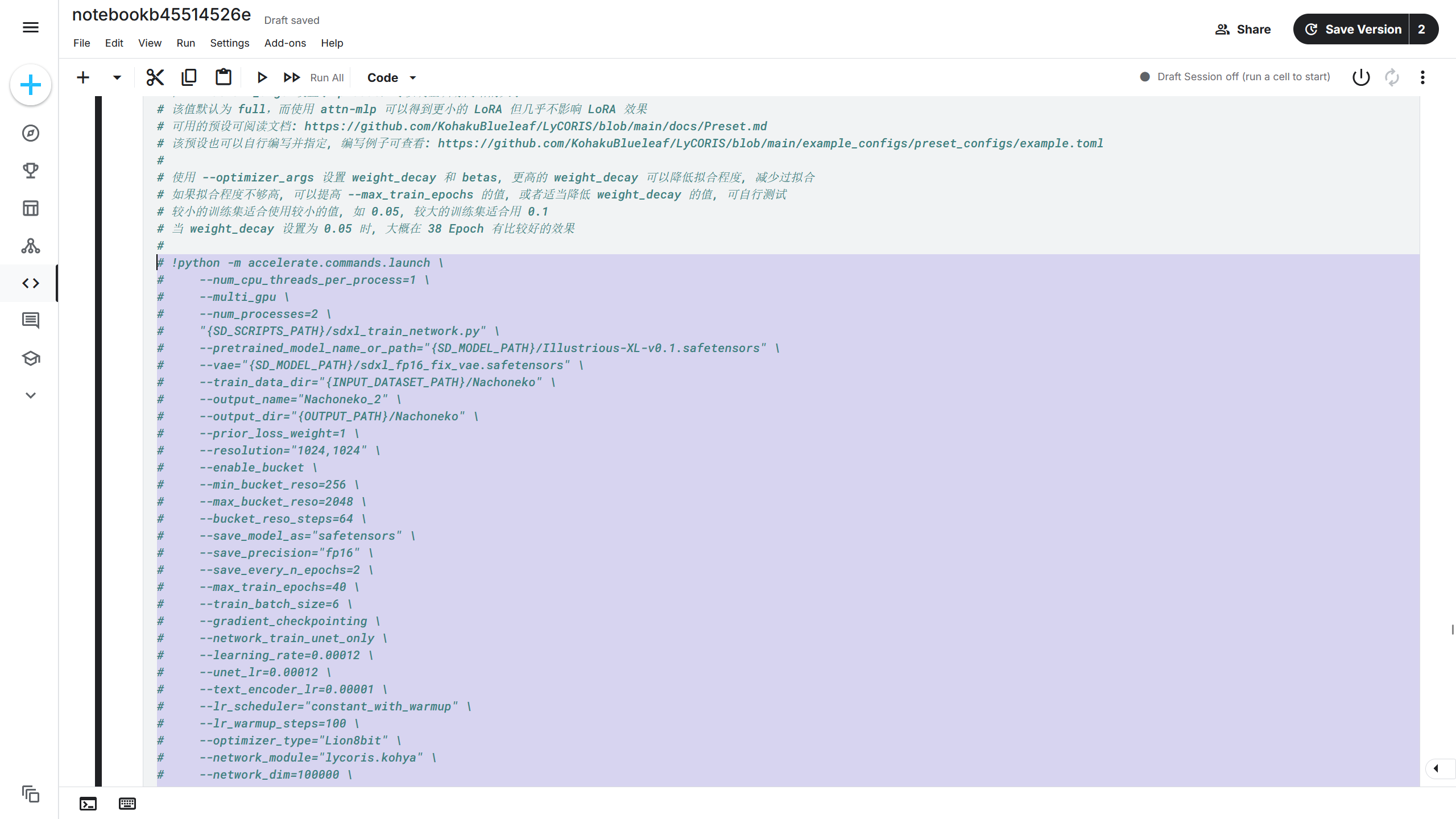
选择后按下Ctrl + /快捷键取消注释,此时训练命令前面的#被清除掉,如果将训练代码加上注释,选择代码后再按下Ctrl + /快捷键即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
|
!python -m pip install lycoris-lora==3.2.0.post2
!python -m accelerate.commands.launch \
--num_cpu_threads_per_process=1 \
--multi_gpu \
--num_processes=2 \
"{SD_SCRIPTS_PATH}/sdxl_train_network.py" \
--pretrained_model_name_or_path="{SD_MODEL_PATH}/Illustrious-XL-v0.1.safetensors" \
--vae="{SD_MODEL_PATH}/sdxl_fp16_fix_vae.safetensors" \
--train_data_dir="{INPUT_DATASET_PATH}/Nachoneko" \
--output_name="Nachoneko_2" \
--output_dir="{OUTPUT_PATH}/Nachoneko" \
--wandb_run_name="Nachoneko" \
--log_tracker_name="lora-Nachoneko" \
--prior_loss_weight=1 \
--resolution="1024,1024" \
--enable_bucket \
--min_bucket_reso=256 \
--max_bucket_reso=4096 \
--bucket_reso_steps=64 \
--save_model_as="safetensors" \
--save_precision="fp16" \
--save_every_n_epochs=1 \
--max_train_epochs=40 \
--train_batch_size=6 \
--gradient_checkpointing \
--network_train_unet_only \
--learning_rate=0.0001 \
--unet_lr=0.0001 \
--text_encoder_lr=0.00001 \
--lr_scheduler="constant_with_warmup" \
--lr_warmup_steps=100 \
--optimizer_type="Lion8bit" \
--network_module="lycoris.kohya" \
--network_dim=100000 \
--network_alpha=100000 \
--network_args \
conv_dim=100000 \
conv_alpha=100000 \
algo=lokr \
dropout=0 \
factor=8 \
train_norm=True \
preset="full" \
--optimizer_args \
weight_decay=0.05 \
betas="0.9,0.95" \
--log_with="{LOG_MODULE}" \
--logging_dir="{OUTPUT_PATH}/logs" \
--caption_extension=".txt" \
--shuffle_caption \
--keep_tokens=0 \
--max_token_length=225 \
--seed=1337 \
--mixed_precision="fp16" \
--xformers \
--cache_latents \
--cache_latents_to_disk \
--persistent_data_loader_workers \
--debiased_estimation_loss \
--vae_batch_size=4 \
--full_fp16
|
现在修改一下大模型路径和训练集路径,即--pretrained_model_name_or_path和--train_data_dir的值,路径根据前面选择的方法得到的路径来选择。比如大模型路径为SD_MODEL_PATH/ill-xl.safetensors,训练集路径为{INPUT_DATASET_PATH}/character_aaaki,则修改后对应的参数为--pretrained_model_name_or_path="{SD_MODEL_PATH}/ill-xl.safetensors"和--train_data_dir="{INPUT_DATASET_PATH}/character_aaaki"。注意这里的{SD_MODEL_PATH}和{INPUT_DATASET_PATH}为变量,在 Jupyter Notebook 的 Shell 调用方法中需要加上{}符号将变量中的值解析为对应的内容。
这里再修改一下模型保存路径和模型的保存的名称,需要修改--output_dir和--output_name的值。比如我想让训练出来的模型保存在lora-character-aaaki文件夹,模型保存的名称为ill-xl-character-aaaki,则修改后对应的参数为--output_dir="{OUTPUT_PATH}/lora-character-aaaki"和--output_name="ill-xl-character-aaaki"。
其他参数保持默认即可,如果了解这些训练参数中的作用,也可以自行修改。修改后的训练命令如下。
命令语法
训练命令的开头为英文的感叹号,也就是!,后面写的是 Shell Script 风格的命令,在每一行的最后使用反斜杠进行换行,也就是\。
每一行之间不能有任何换行空出来。最后一行不需要反斜杠,因为是命令的结束。换句话来说,如果下一行紧跟着命令,上一行的末尾就需要加上反斜杠。
注意反斜杠的后面不能有任何字符,比如空格等。
下面是正确的写法:
1
2
3
4
5
| !python -m accelerate.commands.launch \
--num_cpu_threads_per_process=1 \
--multi_gpu \
--num_processes=2 \
"{SD_SCRIPTS_PATH}/sdxl_train_network.py"
|
下面是错误写法:
(1)
1
2
3
4
5
| !python -m accelerate.commands.launch \
--num_cpu_threads_per_process=1 \
--multi_gpu \
--num_processes=2 \
"{SD_SCRIPTS_PATH}/sdxl_train_network.py"
|
错误写法中反斜杠后面有其他的字符,比如空格,注释。
(2)
1
2
3
4
5
| !python -m accelerate.commands.launch \
--num_cpu_threads_per_process=1 \
--multi_gpu \
--num_processes=2 \
"{SD_SCRIPTS_PATH}/sdxl_train_network.py" \
|
错误写法中最后一行加了反斜杠。
(3)
1
2
3
4
5
6
7
8
9
| !python -m accelerate.commands.launch \
--num_cpu_threads_per_process=1 \
--multi_gpu \
--num_processes=2 \
"{SD_SCRIPTS_PATH}/sdxl_train_network.py"
|
错误写法中每一行多了一个换行空出来。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
|
!python -m pip install lycoris-lora==3.2.0.post2
!python -m accelerate.commands.launch \
--num_cpu_threads_per_process=1 \
--multi_gpu \
--num_processes=2 \
"{SD_SCRIPTS_PATH}/sdxl_train_network.py" \
--pretrained_model_name_or_path="{SD_MODEL_PATH}/ill-xl.safetensors" \
--vae="{SD_MODEL_PATH}/sdxl_fp16_fix_vae.safetensors" \
--train_data_dir="{INPUT_DATASET_PATH}/character_aaaki" \
--output_name="ill-xl-character-aaaki" \
--output_dir="{OUTPUT_PATH}/lora-character-aaaki" \
--wandb_run_name="lora-character-aaaki" \
--log_tracker_name="ill-xl-character-aaaki" \
--prior_loss_weight=1 \
--resolution="1024,1024" \
--enable_bucket \
--min_bucket_reso=256 \
--max_bucket_reso=4096 \
--bucket_reso_steps=64 \
--save_model_as="safetensors" \
--save_precision="fp16" \
--save_every_n_epochs=1 \
--max_train_epochs=40 \
--train_batch_size=6 \
--gradient_checkpointing \
--network_train_unet_only \
--learning_rate=0.0001 \
--unet_lr=0.0001 \
--text_encoder_lr=0.00001 \
--lr_scheduler="constant_with_warmup" \
--lr_warmup_steps=100 \
--optimizer_type="Lion8bit" \
--network_module="lycoris.kohya" \
--network_dim=100000 \
--network_alpha=100000 \
--network_args \
conv_dim=100000 \
conv_alpha=100000 \
algo=lokr \
dropout=0 \
factor=8 \
train_norm=True \
preset="full" \
--optimizer_args \
weight_decay=0.05 \
betas="0.9,0.95" \
--log_with="{LOG_MODULE}" \
--logging_dir="{OUTPUT_PATH}/logs" \
--caption_extension=".txt" \
--shuffle_caption \
--keep_tokens=0 \
--max_token_length=225 \
--seed=1337 \
--mixed_precision="fp16" \
--xformers \
--cache_latents \
--cache_latents_to_disk \
--persistent_data_loader_workers \
--debiased_estimation_loss \
--vae_batch_size=4 \
--full_fp16
|
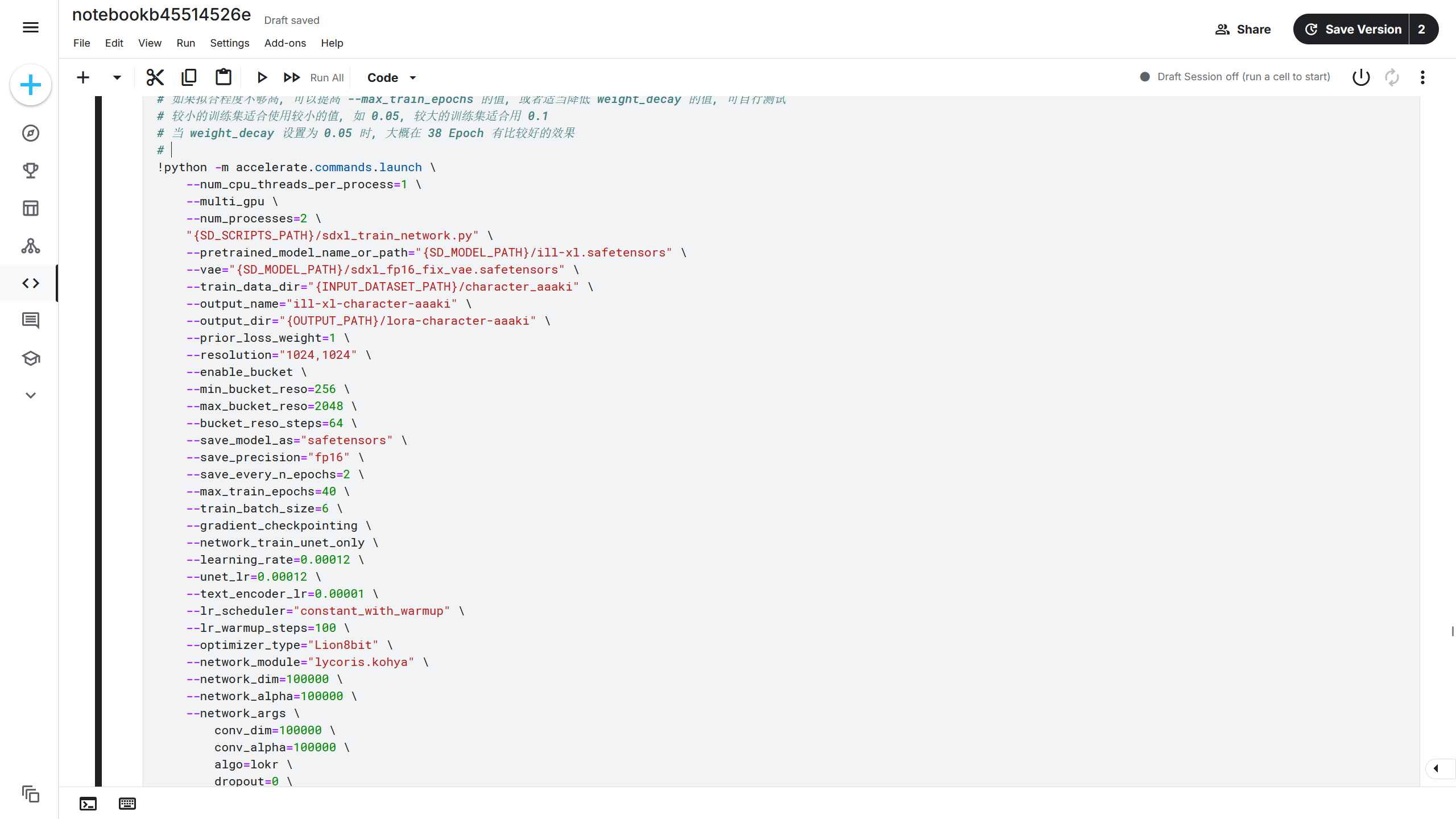
现在模型的训练参数就配置完成了。
toml 格式的训练参数
如果需要 toml 格式的训练命令,比如从 Akegarasu/lora-scripts 训练器中抄写来的训练参数,可以找到 toml 格式的训练参数例子。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
|
|
按照上面的参数来修改一下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
|
toml_file_path = os.path.join(WORKSPACE, "train_config.toml")
toml_content = f"""
pretrained_model_name_or_path = "{SD_MODEL_PATH}/ill-xl.safetensors"
vae = "{SD_MODEL_PATH}/sdxl_fp16_fix_vae.safetensors"
train_data_dir = "{INPUT_DATASET_PATH}/character_aaaki"
output_name = "ill-xl-character-aaaki"
output_dir = "{OUTPUT_PATH}/lora-character-aaaki"
wandb_run_name = "lora-character-aaaki"
log_tracker_name = "ill-xl-character-aaaki"
prior_loss_weight = 1
resolution = "1024,1024"
enable_bucket = true
min_bucket_reso = 256
max_bucket_reso = 4096
bucket_reso_steps = 64
save_model_as = "safetensors"
save_precision = "fp16"
save_every_n_epochs = 1
max_train_epochs = 40
train_batch_size = 6
gradient_checkpointing = true
network_train_unet_only = true
learning_rate = 0.0001
unet_lr = 0.0001
text_encoder_lr = 0.00001
lr_scheduler = "constant_with_warmup"
lr_warmup_steps = 100
optimizer_type = "Lion8bit"
network_module = "lycoris.kohya"
network_dim = 100000
network_alpha = 100000
network_args = [
"conv_dim=100000",
"conv_alpha=100000",
"algo=lokr",
"dropout=0",
"factor=8",
"train_norm=True",
"preset=full",
]
optimizer_args = [
"weight_decay=0.05",
"betas=0.9,0.95",
]
log_with = "{LOG_MODULE}"
logging_dir = "{OUTPUT_PATH}/logs"
caption_extension = ".txt"
shuffle_caption = true
keep_tokens = 0
max_token_length = 225
seed = 1337
mixed_precision = "fp16"
xformers = true
cache_latents = true
cache_latents_to_disk = true
persistent_data_loader_workers = true
debiased_estimation_loss = true
vae_batch_size = 4
full_fp16 = true
""".strip()
if not os.path.exists(os.path.dirname(toml_file_path)):
os.makedirs(toml_file_path, exist_ok=True)
with open(toml_file_path, "w", encoding="utf8") as file:
file.write(toml_content)
!python -m pip install lycoris-lora==3.2.0.post2
!python -m accelerate.commands.launch \
--num_cpu_threads_per_process=1 \
--multi_gpu \
--num_processes=2 \
"{SD_SCRIPTS_PATH}/sdxl_train_network.py" \
--config_file="{toml_file_path}"
|
这样 toml 格式的训练参数就配置好了呢。
该训练参数可能会遇到的问题
该训练参数在使用时会遇到一些训练报错的问题,以下是一些解决方法:
- torch.OutOfMemoryError: Allocation on device would exceed allowed memory. (out of memory)
该训练参数使用了 LyCORIS 模块进行训练,但是新版 LyCORIS 模块需要更高的显存进行训练,而这套训练参数在训练时剩余的显存很少,也就导致使用新版 LyCORIS 模块会导致显存不足的问题,一个解决方法是降低train_batch_size的大小,另一种方法是降级 LyCORIS 模块,在安装环境部分新加一条命令:
1
| !uv pip install lycoris-lora==3.2.0.post2
|
降级后应该就能正常使用这套参数而不会发生显存不足的问题了。
- AttributeError: module ‘wandb.util’ has no attribute ‘_has_internet’
如果在使用 WandB 作为训练日志模块时出现这种错误,可以尝试降级 WandB,在安装环境部分新加一条命令:
1
| !uv pip install wandb==0.22.3
|
这样应该就能修复这个报错。
10. 启动训练脚本
点击 Kaggle 右上角的 Save Version(保存版本),在 VERSION TYPE(版本种类)选项中选择Save & Run All (Commit)(保存并运行所有单元 (提交记录)),再点击右下角的 Save(保存),此时将依次运行训练脚本中的单元。
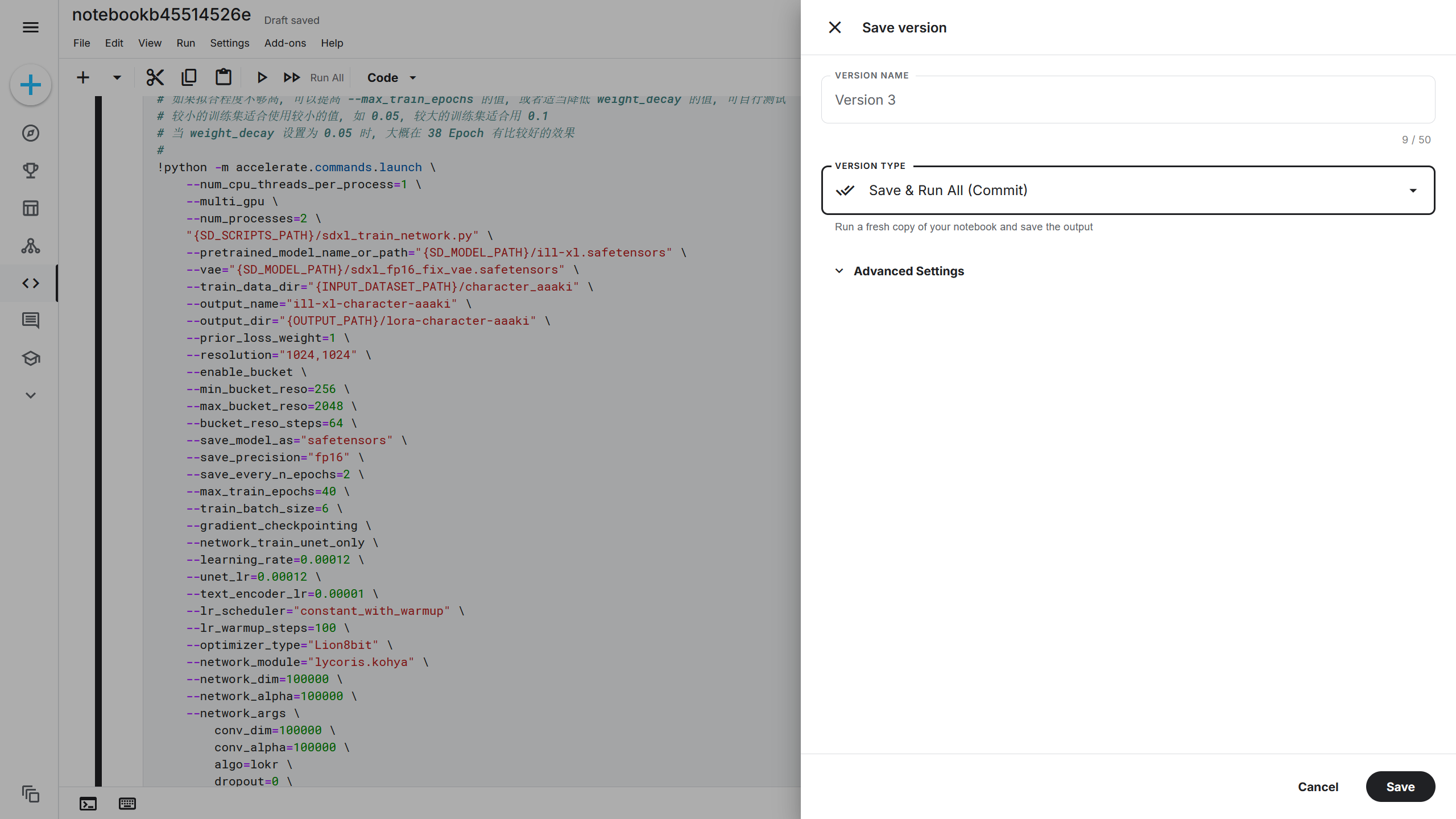
运行后点击 Kaggle 左下角的按钮可以打开 Active Event(运行中的实例),可以看到刚刚启动的训练脚本。
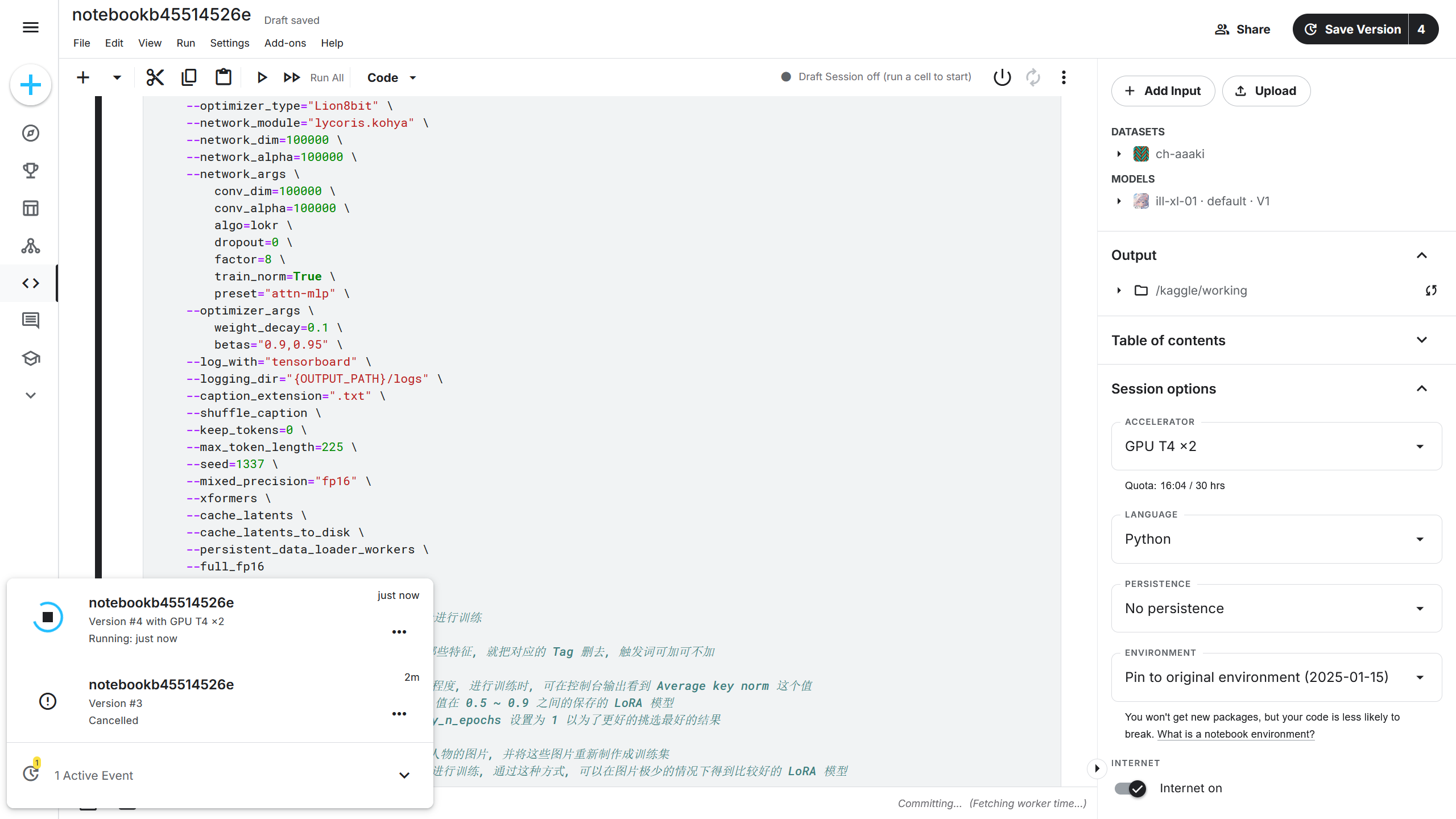
点击后可以在 Logs(日志)查看实时的训练日志。
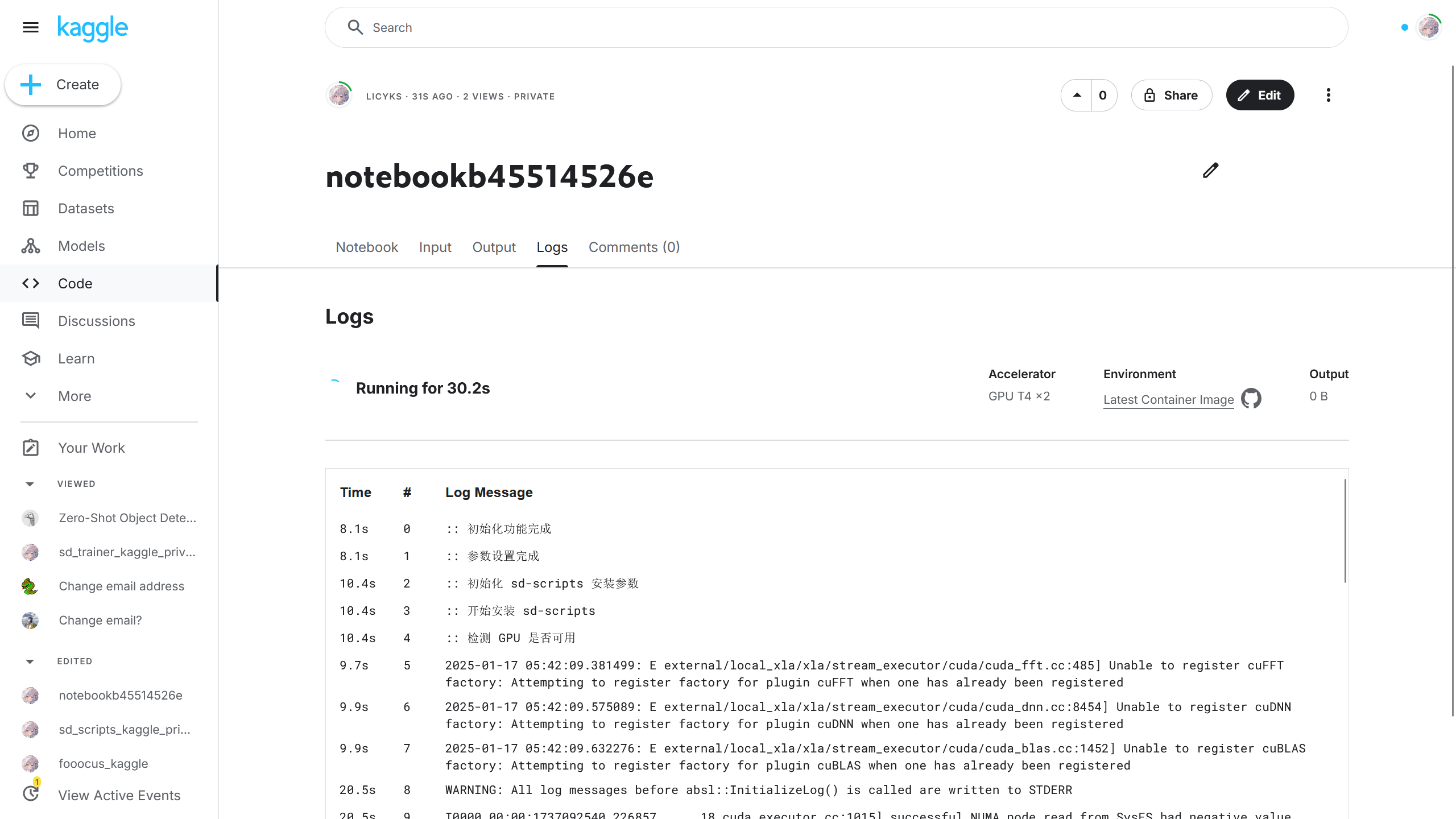
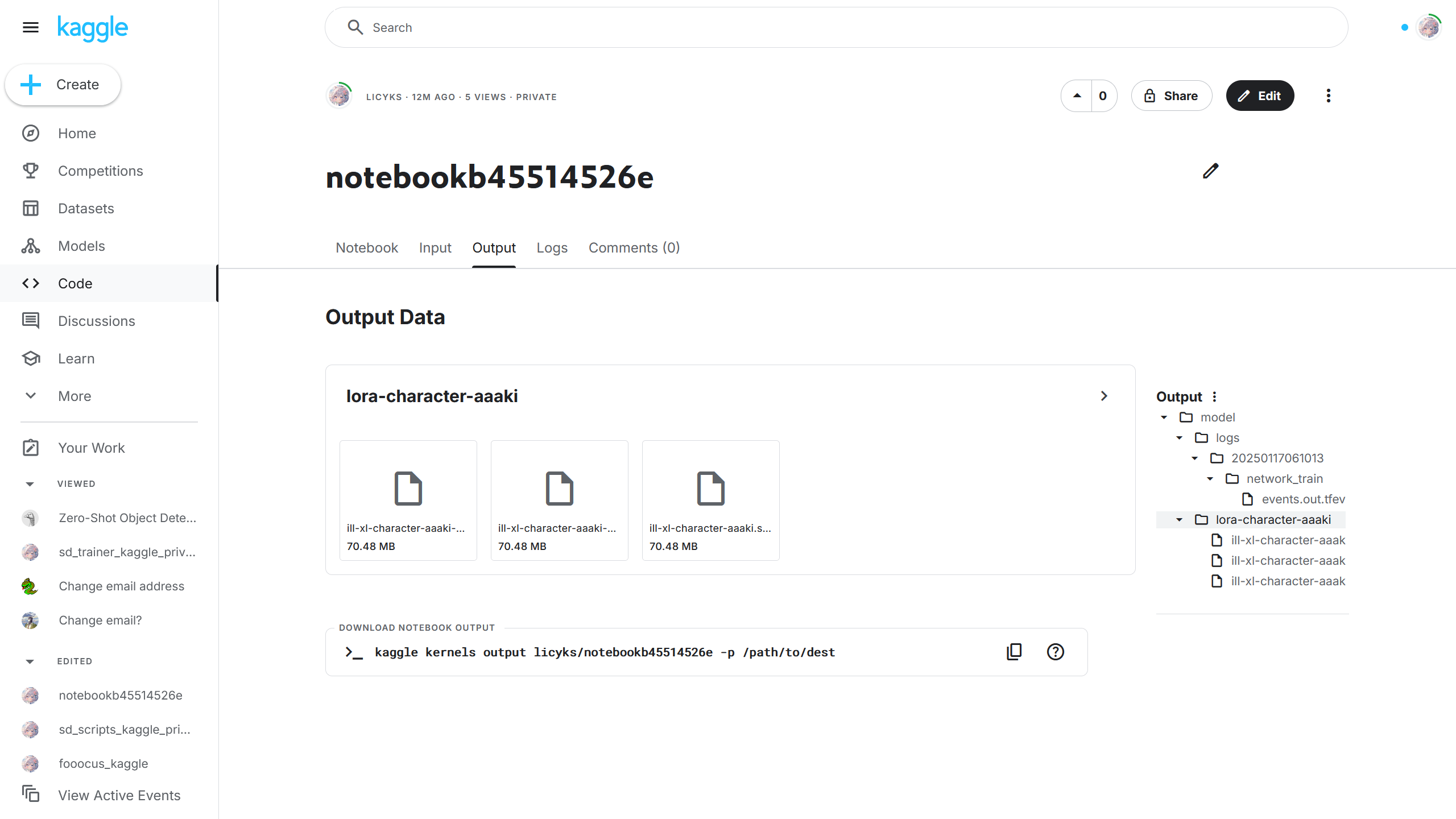
11. 下载训练好的模型
如果训练成功后,可以在 Kaggle Output(Kaggle 输出)中查看训练好的模型,选择其中一个模型后可以下载该模型。
如果在模型上传设置启用了 HuggingFace 和 ModelScope,在 HuggingFace 和 ModelScope 上的仓库中也可以下载模型。
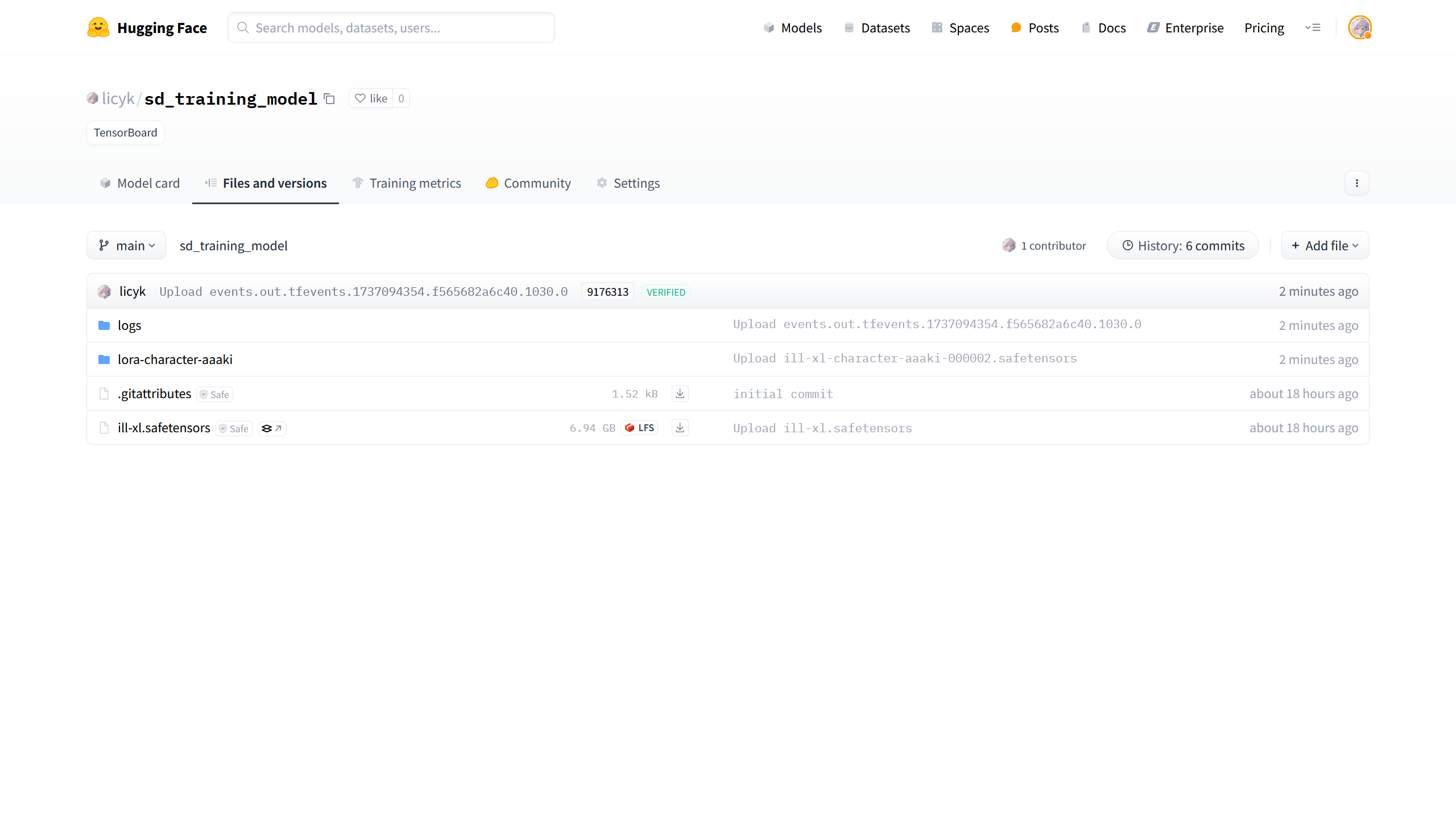
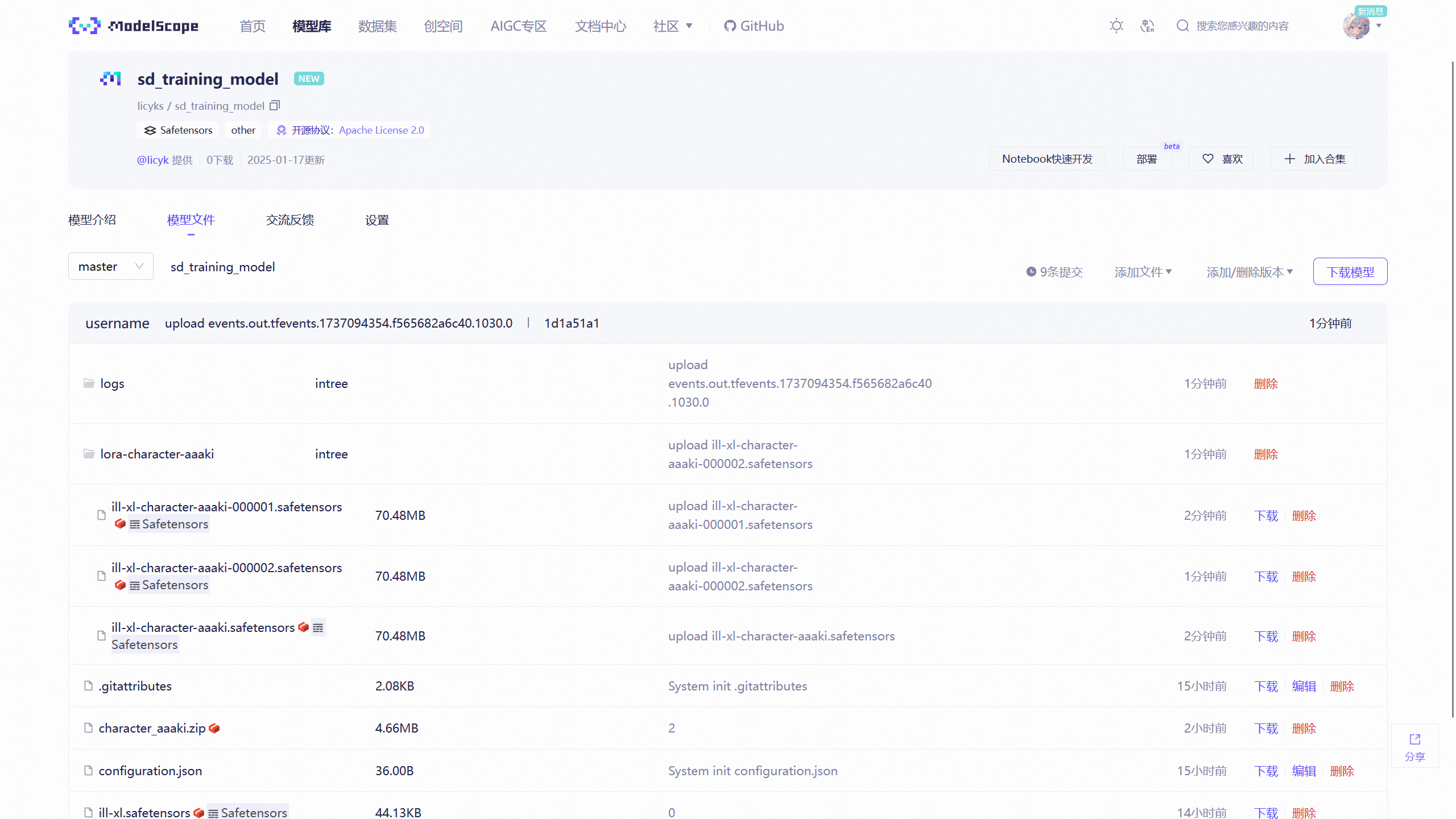
将下载下来的模型导入 Stable Diffusion WebUI,ComfyUI 等软件中即可使用。
只有第一次使用 Kaggle 训练模型时会比较麻烦,第二次训练时,因为有之前配置好的参数,所以需要修改训练脚本的地方就非常少了,弄起来就简单许多了呢。